Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget Layer Regularization for Continual Learning Using Cramer-Wold Generator
Paper and Code
Nov 15, 2021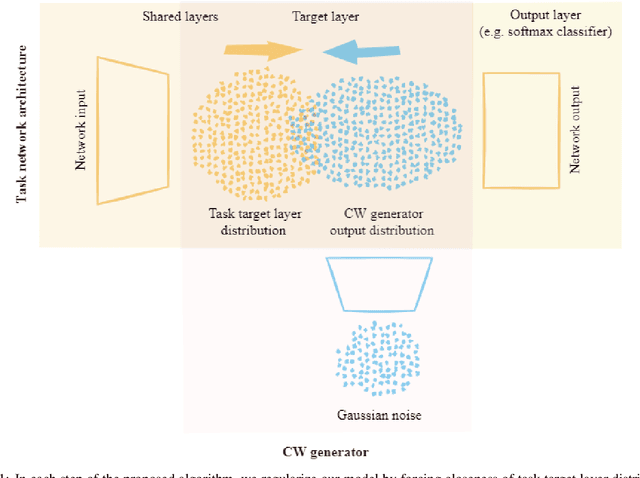
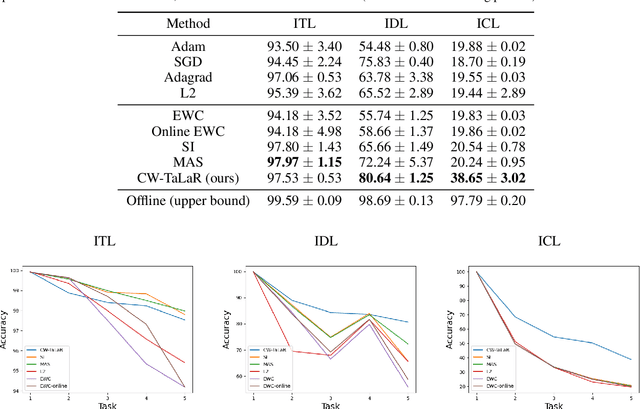
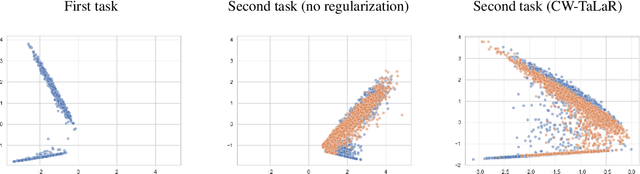
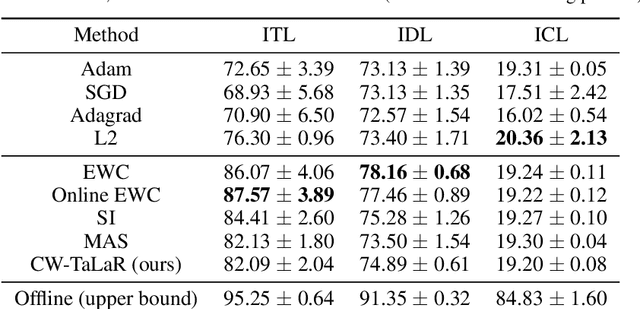
We propose an effective regularization strategy (CW-TaLaR) for solving continual learning problems. It uses a penalizing term expressed by the Cramer-Wold distance between two probability distributions defined on a target layer of an underlying neural network that is shared by all tasks, and the simple architecture of the Cramer-Wold generator for modeling output data representation. Our strategy preserves target layer distribution while learning a new task but does not require remembering previous tasks' datasets. We perform experiments involving several common supervised frameworks, which prove the competitiveness of the CW-TaLaR method in comparison to a few existing state-of-the-art continual learning models.
* The paper is under consideration at Computer Vision and Image
Understanding
View paper on
 OpenReview
OpenReview