 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAP-DLND 1.0 : A Corpus for Document Level Novelty Detection
Paper and Code
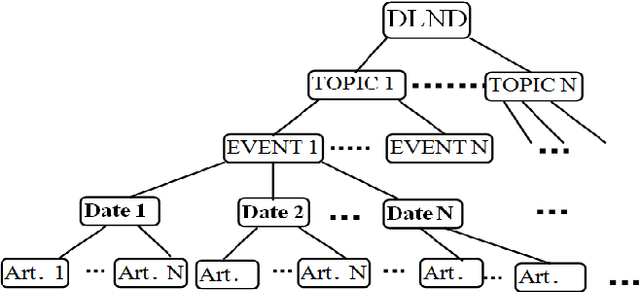


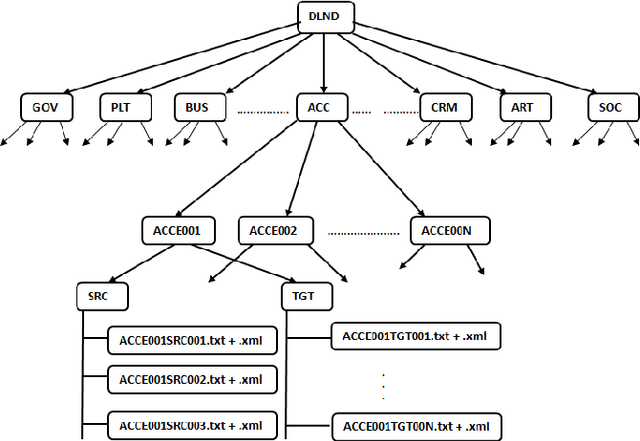
Detecting novelty of an entire document is an Artificial Intelligence (AI) frontier problem that has widespread NLP applications, such as extractive document summarization, tracking development of news events, predicting impact of scholarly articles, etc. Important though the problem is, we are unaware of any benchmark document level data that correctly addresses the evaluation of automatic novelty detection techniques in a classification framework. To bridge this gap, we present here a resource for benchmarking the techniques for document level novelty detection. We create the resource via event-specific crawling of news documents across several domains in a periodic manner. We release the annotated corpus with necessary statistics and show its use with a developed system for the problem in concern.