 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming Momentum in a Distributed Asynchronous Environment
Paper and Code

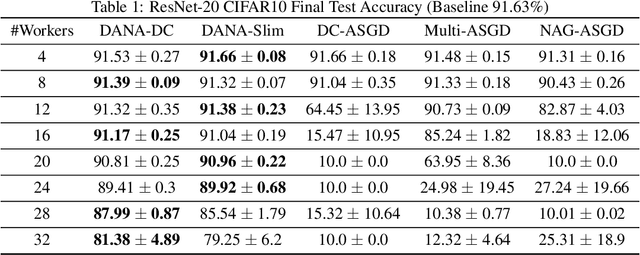
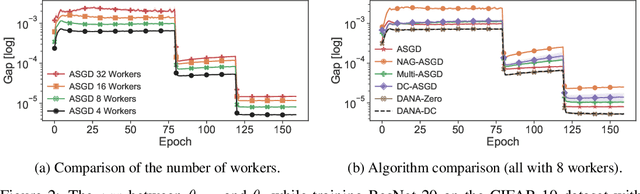
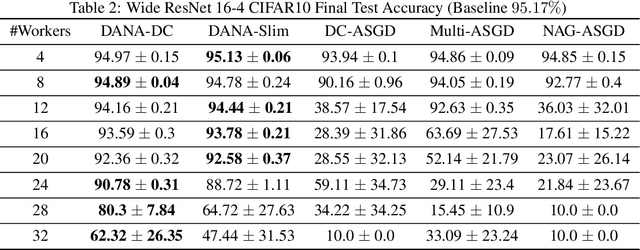
Although distributed computing can significantly reduce the training time of deep neural networks, scaling the training process while maintaining high efficiency and final accuracy is challenging. Distributed asynchronous training enjoys near-linear speedup, but asynchrony causes gradient staleness, the main difficulty in scaling stochastic gradient descent to large clusters. Momentum, which is often used to accelerate convergence and escape local minima, exacerbates the gradient staleness, thereby hindering convergence. We propose DANA: a novel asynchronous distributed technique which is based on a new gradient staleness measure that we call the gap. By minimizing the gap, DANA mitigates the gradient staleness, despite using momentum, and therefore scales to large clusters while maintaining high final accuracy and fast convergence. DANA adapts Nesterov's Accelerated Gradient to a distributed setting, computing the gradient on an estimated future position of the model's parameters. In turn, we show that DANA's estimation of the future position amplifies the use of a Taylor expansion, which relies on a fast Hessian approximation, making it much more effective and accurate. Our evaluation on the CIFAR and ImageNet datasets shows that DANA outperforms existing methods, in both final accuracy and convergence speed.