 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-SNE Is Not Optimized to Reveal Clusters in Data
Paper and Code
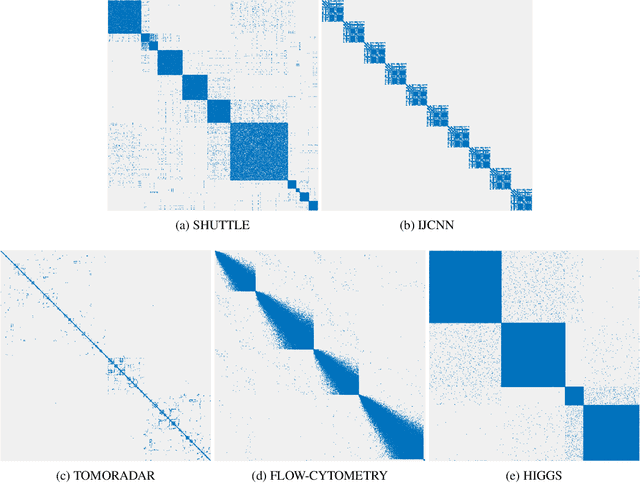
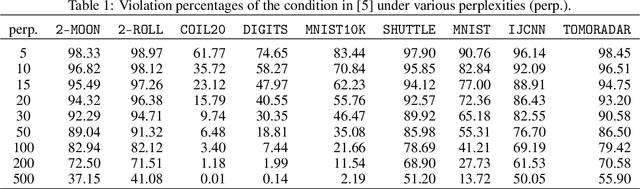

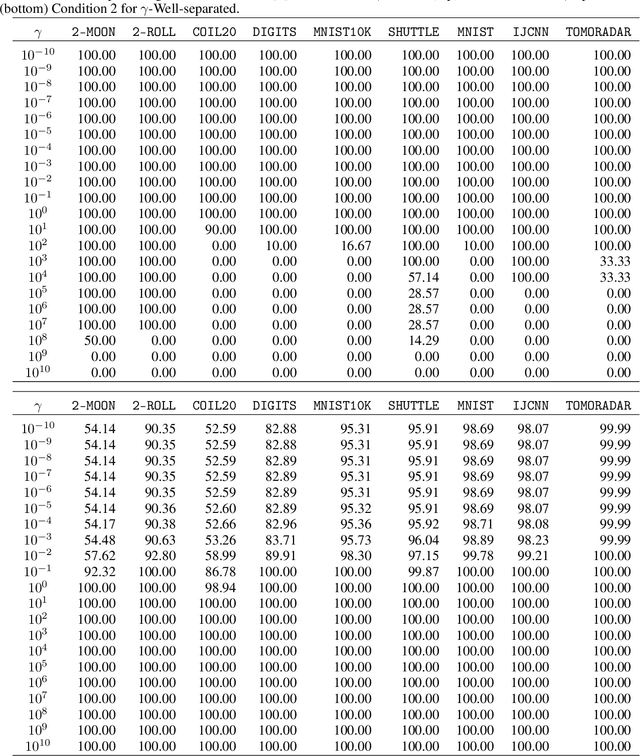
Cluster visualization is an essential task for nonlinear dimensionality reduction as a data analysis tool. It is often believed that Student t-Distributed Stochastic Neighbor Embedding (t-SNE) can show clusters for well clusterable data, with a smaller Kullback-Leibler divergence corresponding to a better quality. There was even theoretical proof for the guarantee of this property. However, we point out that this is not necessarily the case -- t-SNE may leave clustering patterns hidden despite strong signals present in the data. Extensive empirical evidence is provided to support our claim. First, several real-world counter-examples are presented, where t-SNE fails even if the input neighborhoods are well clusterable. Tuning hyperparameters in t-SNE or using better optimization algorithms does not help solve this issue because a better t-SNE learning objective can correspond to a worse cluster embedding. Second, we check the assumptions in the clustering guarantee of t-SNE and find they are often violated for real-world data sets.