 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-Net: A Template-Supervised Network for Task-specific Feature Extraction in Biomedical Image Analysis
Paper and Code
Feb 19, 2020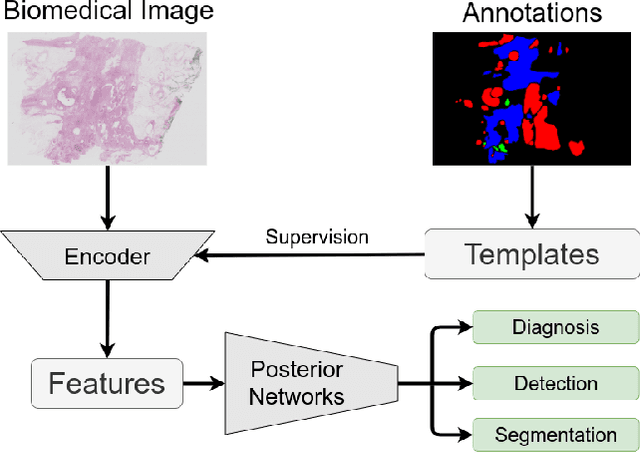

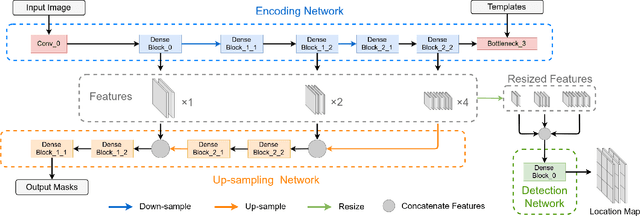
Existing deep learning methods depend on an encoder-decoder structure to learn feature representation from the segmentation annotation in biomedical image analysis. However, the effectiveness of feature extraction under this structure decreases due to the indirect optimization process, limited training data size, and simplex supervision method. In this paper, we propose a template-supervised network T-Net for task-specific feature extraction. Specifically, we first obtain templates from pixel-level annotations by down-sampling binary masks of recognition targets according to specific tasks. Then, we directly train the encoding network under the supervision of the derived task-specific templates. Finally, we combine the resulting encoding network with a posterior network for the specific task, e.g. an up-sampling network for segmentation or a region proposal network for detection. Extensive experiments on three public datasets (BraTS-17, MoNuSeg and IDRiD) show that T-Net achieves competitive results to the state-of-the-art methods and superior performance to an encoder-decoder based network. To the best of our knowledge, this is the first in-depth study to improve feature extraction by directly supervise the encoding network and by applying task-specific supervision in biomedical image analysis.