 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Policies That Account For Human Execution Errors Caused By State-Aliasing In Markov Decision Processes
Paper and Code
Sep 20, 2021
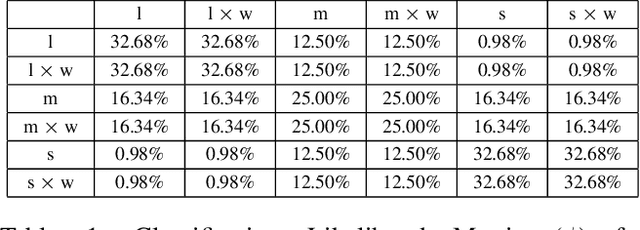

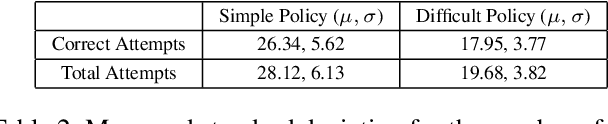
When humans are given a policy to execute, there can be policy execution errors and deviations in execution if there is uncertainty in identifying a state. So an algorithm that computes a policy for a human to execute ought to consider these effects in its computations. An optimal MDP policy that is poorly executed (because of a human agent) maybe much worse than another policy that is executed with fewer errors. In this paper, we consider the problems of erroneous execution and execution delay when computing policies for a human agent that would act in a setting modeled by a Markov Decision Process. We present a framework to model the likelihood of policy execution errors and likelihood of non-policy actions like inaction (delays) due to state uncertainty. This is followed by a hill climbing algorithm to search for good policies that account for these errors. We then use the best policy found by hill climbing with a branch and bound algorithm to find the optimal policy. We show experimental results in a Gridworld domain and analyze the performance of the two algorithms. We also present human studies that verify if our assumptions on policy execution by humans under state-aliasing are reasonable.