 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyntactic representation learning for neural network based TTS with syntactic parse tree traversal
Paper and Code
Dec 13, 2020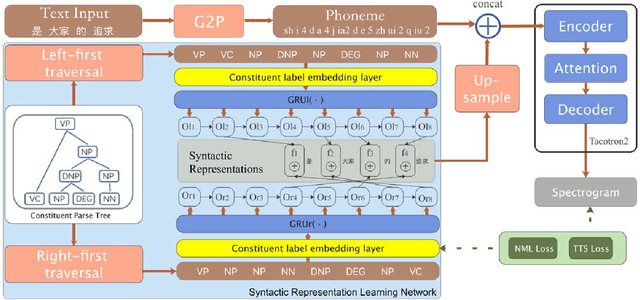

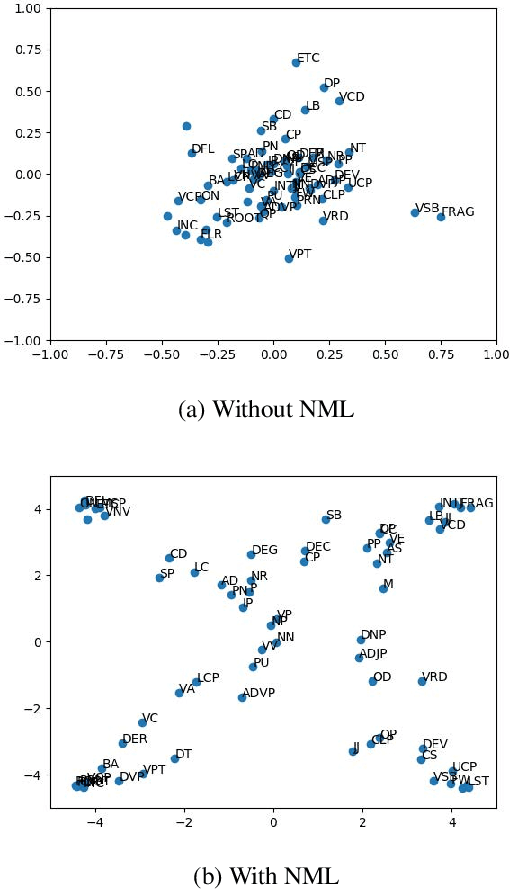
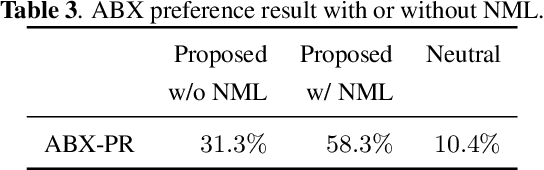
Syntactic structure of a sentence text is correlated with the prosodic structure of the speech that is crucial for improving the prosody and naturalness of a text-to-speech (TTS) system. Nowadays TTS systems usually try to incorporate syntactic structure information with manually designed features based on expert knowledge. In this paper, we propose a syntactic representation learning method based on syntactic parse tree traversal to automatically utilize the syntactic structure information. Two constituent label sequences are linearized through left-first and right-first traversals from constituent parse tree. Syntactic representations are then extracted at word level from each constituent label sequence by a corresponding uni-directional gated recurrent unit (GRU) network. Meanwhile, nuclear-norm maximization loss is introduced to enhance the discriminability and diversity of the embeddings of constituent labels. Upsampled syntactic representations and phoneme embeddings are concatenated to serve as the encoder input of Tacotron2. Experimental results demonstrate the effectiveness of our proposed approach, with mean opinion score (MOS) increasing from 3.70 to 3.82 and ABX preference exceeding by 17% compared with the baseline. In addition, for sentences with multiple syntactic parse trees, prosodic differences can be clearly perceived from the synthesized speeches.