 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymmetric (Optimistic) Natural Policy Gradient for Multi-agent Learning with Parameter Convergence
Paper and Code
Oct 23, 2022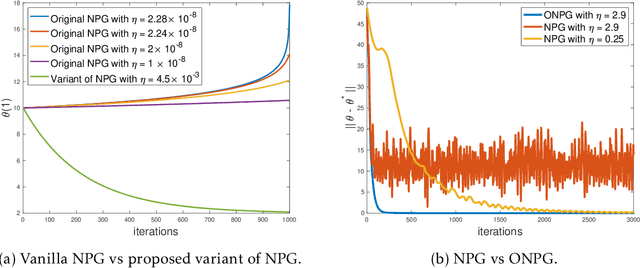
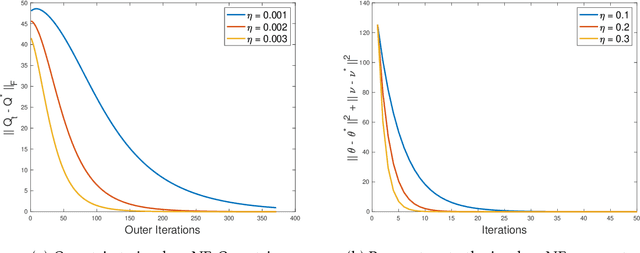
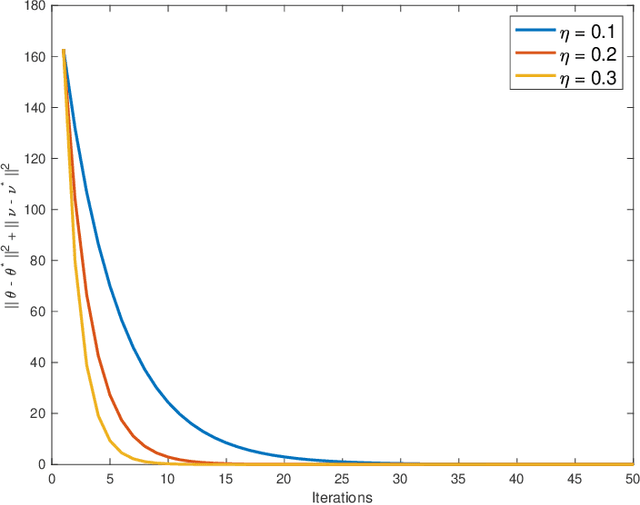
Multi-agent interactions are increasingly important in the context of reinforcement learning, and the theoretical foundations of policy gradient methods have attracted surging research interest. We investigate the global convergence of natural policy gradient (NPG) algorithms in multi-agent learning. We first show that vanilla NPG may not have parameter convergence, i.e., the convergence of the vector that parameterizes the policy, even when the costs are regularized (which enabled strong convergence guarantees in the policy space in the literature). This non-convergence of parameters leads to stability issues in learning, which becomes especially relevant in the function approximation setting, where we can only operate on low-dimensional parameters, instead of the high-dimensional policy. We then propose variants of the NPG algorithm, for several standard multi-agent learning scenarios: two-player zero-sum matrix and Markov games, and multi-player monotone games, with global last-iterate parameter convergence guarantees. We also generalize the results to certain function approximation settings. Note that in our algorithms, the agents take symmetric roles. Our results might also be of independent interest for solving nonconvex-nonconcave minimax optimization problems with certain structures. Simulations are also provided to corroborate our theoretical findings.