 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyllable Discovery and Cross-Lingual Generalization in a Visually Grounded, Self-Supervised Speech Mode
Paper and Code
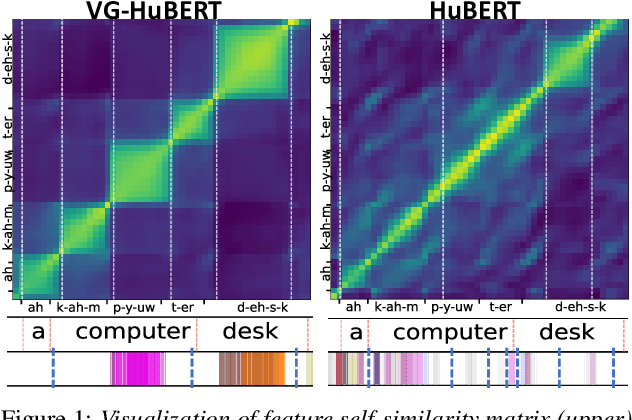



In this paper, we show that representations capturing syllabic units emerge when training a self-supervised speech model with a visually-grounded training objective. We demonstrate that a nearly identical model architecture (HuBERT) trained with a masked language modeling loss does not exhibit this same ability, suggesting that the visual grounding objective is responsible for the emergence of this phenomenon. We propose the use of a minimum cut algorithm to automatically predict syllable boundaries in speech, followed by a 2-stage clustering method to group identical syllables together. We show that our model not only outperforms a state-of-the-art syllabic segmentation method on the language it was trained on (English), but also generalizes in a zero-shot fashion to Estonian. Finally, we show that the same model is capable of zero-shot generalization for a word segmentation task on 4 other languages from the Zerospeech Challenge, in some cases beating the previous state-of-the-art.