 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwinFuse: A Residual Swin Transformer Fusion Network for Infrared and Visible Images
Paper and Code



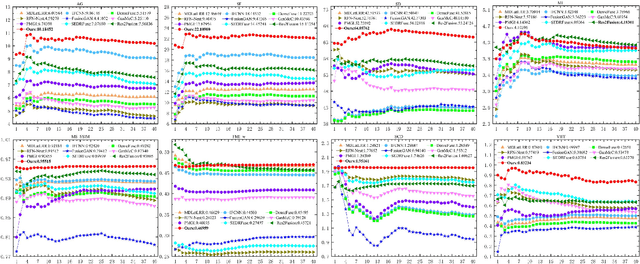
The existing deep learning fusion methods mainly concentrate on the convolutional neural networks, and few attempts are made with transformer. Meanwhile, the convolutional operation is a content-independent interaction between the image and convolution kernel, which may lose some important contexts and further limit fusion performance. Towards this end, we present a simple and strong fusion baseline for infrared and visible images, namely\textit{ Residual Swin Transformer Fusion Network}, termed as SwinFuse. Our SwinFuse includes three parts: the global feature extraction, fusion layer and feature reconstruction. In particular, we build a fully attentional feature encoding backbone to model the long-range dependency, which is a pure transformer network and has a stronger representation ability compared with the convolutional neural networks. Moreover, we design a novel feature fusion strategy based on $L_{1}$-norm for sequence matrices, and measure the corresponding activity levels from row and column vector dimensions, which can well retain competitive infrared brightness and distinct visible details. Finally, we testify our SwinFuse with nine state-of-the-art traditional and deep learning methods on three different datasets through subjective observations and objective comparisons, and the experimental results manifest that the proposed SwinFuse obtains surprising fusion performance with strong generalization ability and competitive computational efficiency. The code will be available at https://github.com/Zhishe-Wang/SwinFuse.