 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupport Vector Machines with the Hard-Margin Loss: Optimal Training via Combinatorial Benders' Cuts
Paper and Code
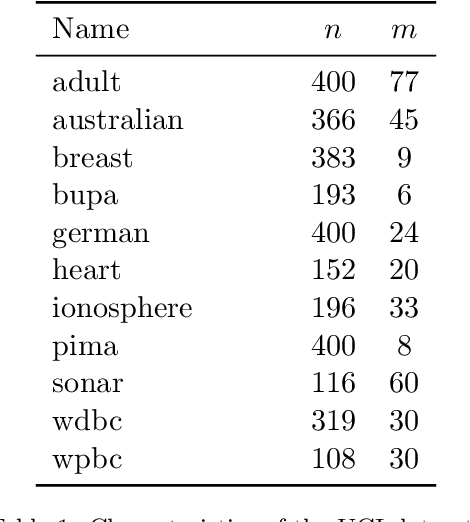
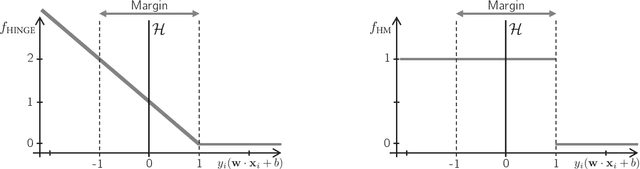

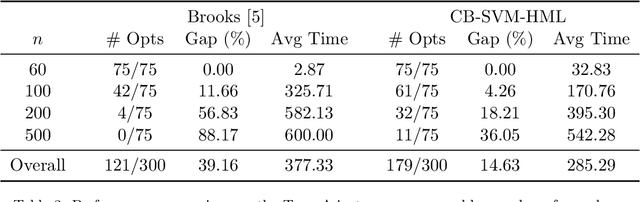
The classical hinge-loss support vector machines (SVMs) model is sensitive to outlier observations due to the unboundedness of its loss function. To circumvent this issue, recent studies have focused on non-convex loss functions, such as the hard-margin loss, which associates a constant penalty to any misclassified or within-margin sample. Applying this loss function yields much-needed robustness for critical applications but it also leads to an NP-hard model that makes training difficult, since current exact optimization algorithms show limited scalability, whereas heuristics are not able to find high-quality solutions consistently. Against this background, we propose new integer programming strategies that significantly improve our ability to train the hard-margin SVM model to global optimality. We introduce an iterative sampling and decomposition approach, in which smaller subproblems are used to separate combinatorial Benders' cuts. Those cuts, used within a branch-and-cut algorithm, permit to converge much more quickly towards a global optimum. Through extensive numerical analyses on classical benchmark data sets, our solution algorithm solves, for the first time, 117 new data sets to optimality and achieves a reduction of 50% in the average optimality gap for the hardest datasets of the benchmark.