 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Convex Clustering
Paper and Code
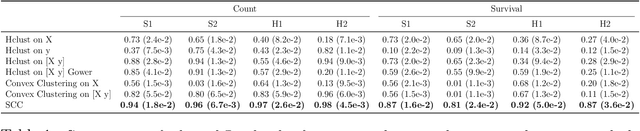
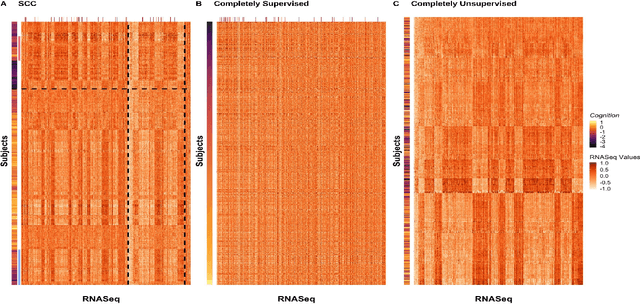
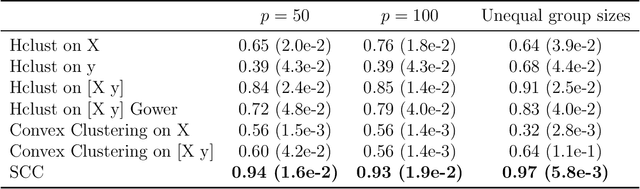
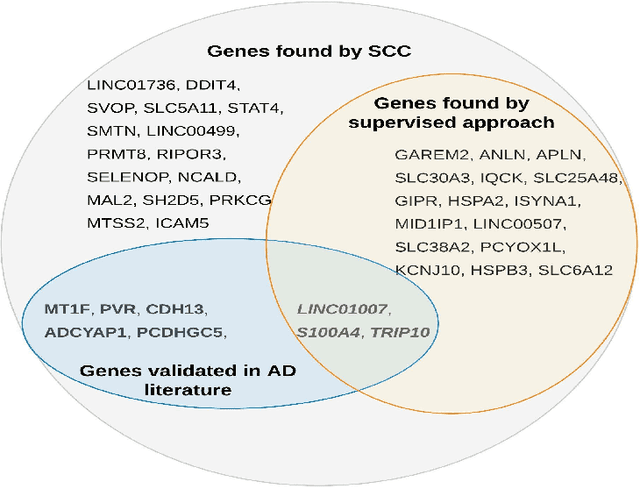
Clustering has long been a popular unsupervised learning approach to identify groups of similar objects and discover patterns from unlabeled data in many applications. Yet, coming up with meaningful interpretations of the estimated clusters has often been challenging precisely due to its unsupervised nature. Meanwhile, in many real-world scenarios, there are some noisy supervising auxiliary variables, for instance, subjective diagnostic opinions, that are related to the observed heterogeneity of the unlabeled data. By leveraging information from both supervising auxiliary variables and unlabeled data, we seek to uncover more scientifically interpretable group structures that may be hidden by completely unsupervised analyses. In this work, we propose and develop a new statistical pattern discovery method named Supervised Convex Clustering (SCC) that borrows strength from both information sources and guides towards finding more interpretable patterns via a joint convex fusion penalty. We develop several extensions of SCC to integrate different types of supervising auxiliary variables, to adjust for additional covariates, and to find biclusters. We demonstrate the practical advantages of SCC through simulations and a case study on Alzheimer's Disease genomics. Specifically, we discover new candidate genes as well as new subtypes of Alzheimer's Disease that can potentially lead to better understanding of the underlying genetic mechanisms responsible for the observed heterogeneity of cognitive decline in older adults.