 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Contrastive Learning for Pre-trained Language Model Fine-tuning
Paper and Code
Nov 12, 2020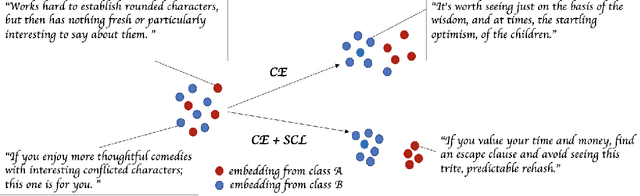


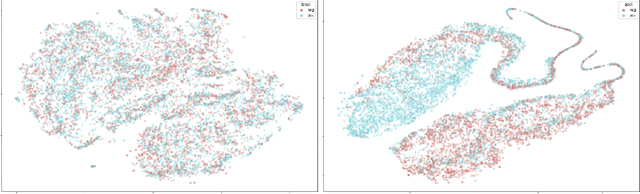
State-of-the-art natural language understanding classification models follow two-stages: pre-training a large language model on an auxiliary task, and then fine-tuning the model on a task-specific labeled dataset using cross-entropy loss. Cross-entropy loss has several shortcomings that can lead to sub-optimal generalization and instability. Driven by the intuition that good generalization requires capturing the similarity between examples in one class and contrasting them with examples in other classes, we propose a supervised contrastive learning (SCL) objective for the fine-tuning stage. Combined with cross-entropy, the SCL loss we propose obtains improvements over a strong RoBERTa-Large baseline on multiple datasets of the GLUE benchmark in both the high-data and low-data regimes, and it does not require any specialized architecture, data augmentation of any kind, memory banks, or additional unsupervised data. We also demonstrate that the new objective leads to models that are more robust to different levels of noise in the training data, and can generalize better to related tasks with limited labeled task data.