 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperresolution and Segmentation of OCT scans using Multi-Stage adversarial Guided Attention Training
Paper and Code
Jun 10, 2022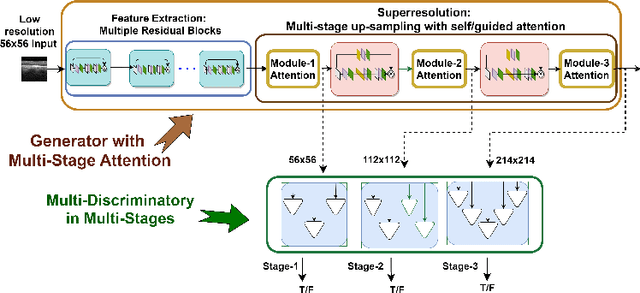

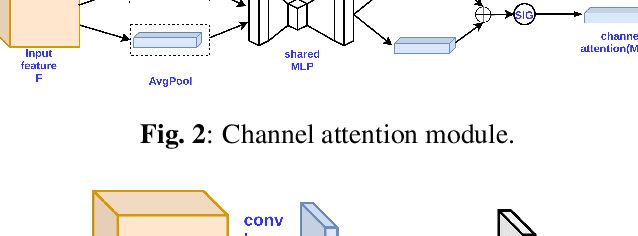
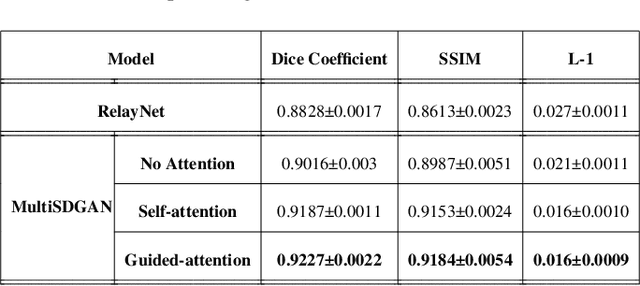
Optical coherence tomography (OCT) is one of the non-invasive and easy-to-acquire biomarkers (the thickness of the retinal layers, which is detectable within OCT scans) being investigated to diagnose Alzheimer's disease (AD). This work aims to segment the OCT images automatically; however, it is a challenging task due to various issues such as the speckle noise, small target region, and unfavorable imaging conditions. In our previous work, we have proposed the multi-stage & multi-discriminatory generative adversarial network (MultiSDGAN) to translate OCT scans in high-resolution segmentation labels. In this investigation, we aim to evaluate and compare various combinations of channel and spatial attention to the MultiSDGAN architecture to extract more powerful feature maps by capturing rich contextual relationships to improve segmentation performance. Moreover, we developed and evaluated a guided mutli-stage attention framework where we incorporated a guided attention mechanism by forcing an L-1 loss between a specifically designed binary mask and the generated attention maps. Our ablation study results on the WVU-OCT data-set in five-fold cross-validation (5-CV) suggest that the proposed MultiSDGAN with a serial attention module provides the most competitive performance, and guiding the spatial attention feature maps by binary masks further improves the performance in our proposed network. Comparing the baseline model with adding the guided-attention, our results demonstrated relative improvements of 21.44% and 19.45% on the Dice coefficient and SSIM, respectively.