 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummarizing Differences between Text Distributions with Natural Language
Paper and Code

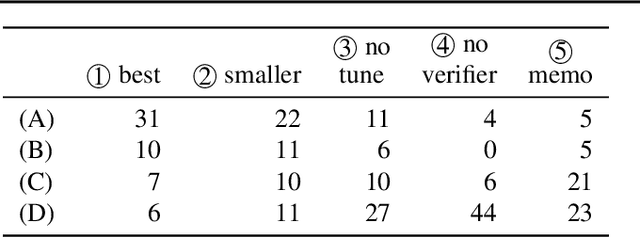


How do two distributions of texts differ? Humans are slow at answering this, since discovering patterns might require tediously reading through hundreds of samples. We propose to automatically summarize the differences by "learning a natural language hypothesis": given two distributions $D_{0}$ and $D_{1}$, we search for a description that is more often true for $D_{1}$, e.g., "is military-related." To tackle this problem, we fine-tune GPT-3 to propose descriptions with the prompt: "[samples of $D_{0}$] + [samples of $D_{1}$] + the difference between them is _____". We then re-rank the descriptions by checking how often they hold on a larger set of samples with a learned verifier. On a benchmark of 54 real-world binary classification tasks, while GPT-3 Curie (13B) only generates a description similar to human annotation 7% of the time, the performance reaches 61% with fine-tuning and re-ranking, and our best system using GPT-3 Davinci (175B) reaches 76%. We apply our system to describe distribution shifts, debug dataset shortcuts, summarize unknown tasks, and label text clusters, and present analyses based on automatically generated descriptions.