Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSufficient Representations for Categorical Variables
Paper and Code
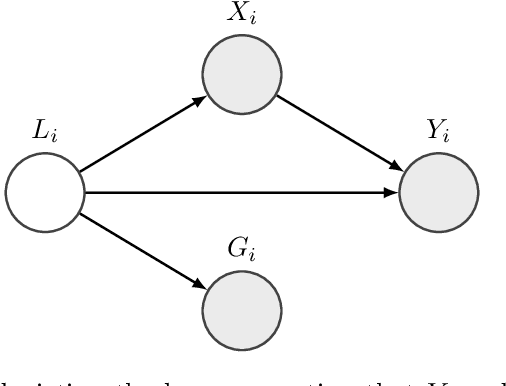
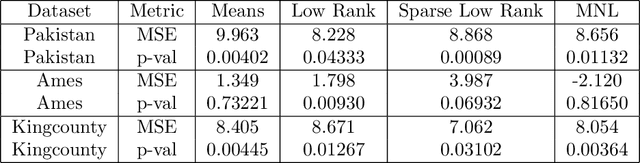
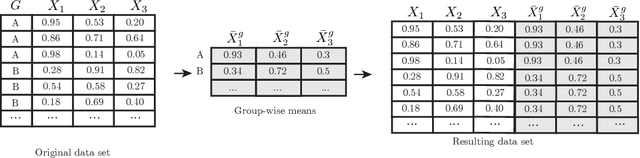
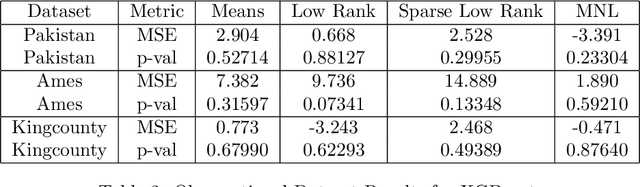
Many learning algorithms require categorical data to be transformed into real vectors before it can be used as input. Often, categorical variables are encoded as one-hot (or dummy) vectors. However, this mode of representation can be wasteful since it adds many low-signal regressors, especially when the number of unique categories is large. In this paper, we investigate simple alternative solutions for universally consistent estimators that rely on lower-dimensional real-valued representations of categorical variables that are "sufficient" in the sense that no predictive information is lost. We then compare preexisting and proposed methods on simulated and observational datasets.
View paper on