Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubjective Assessment of Text Complexity: A Dataset for German Language
Paper and Code
Apr 16, 2019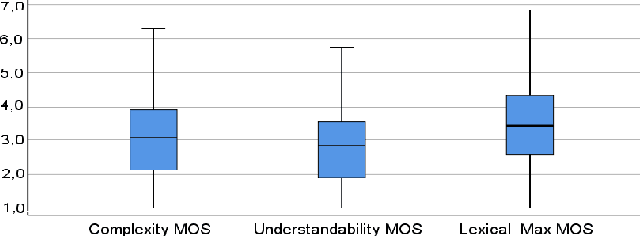

This paper presents TextComplexityDE, a dataset consisting of 1000 sentences in German language taken from 23 Wikipedia articles in 3 different article-genres to be used for developing text-complexity predictor models and automatic text simplification in German language. The dataset includes subjective assessment of different text-complexity aspects provided by German learners in level A and B. In addition, it contains manual simplification of 250 of those sentences provided by native speakers and subjective assessment of the simplified sentences by participants from the target group. The subjective ratings were collected using both laboratory studies and crowdsourcing approach.
View paper on