 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleMaster: Towards Flexible Stylized Image Generation with Diffusion Models
Paper and Code
May 24, 2024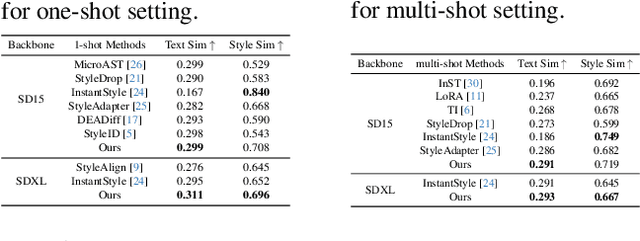
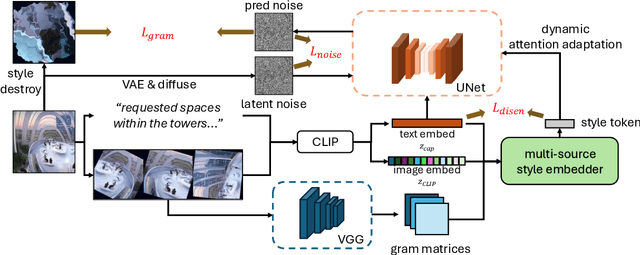
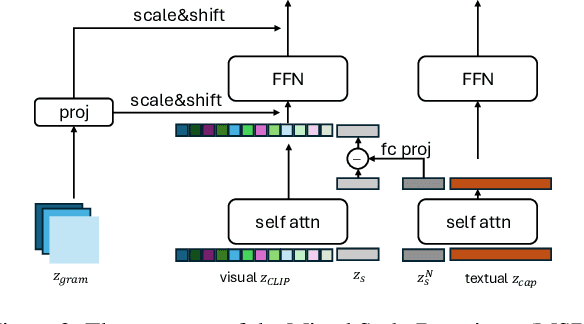

Stylized Text-to-Image Generation (STIG) aims to generate images based on text prompts and style reference images. We in this paper propose a novel framework dubbed as StyleMaster for this task by leveraging pretrained Stable Diffusion (SD), which tries to solve the previous problems such as insufficient style and inconsistent semantics. The enhancement lies in two novel module, namely multi-source style embedder and dynamic attention adapter. In order to provide SD with better style embeddings, we propose the multi-source style embedder considers both global and local level visual information along with textual one, which provide both complementary style-related and semantic-related knowledge. Additionally, aiming for better balance between the adaptor capacity and semantic control, the proposed dynamic attention adapter is applied to the diffusion UNet in which adaptation weights are dynamically calculated based on the style embeddings. Two objective functions are introduced to optimize the model together with denoising loss, which can further enhance semantic and style consistency. Extensive experiments demonstrate the superiority of StyleMaster over existing methods, rendering images with variable target styles while successfully maintaining the semantic information from the text prompts.