 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTT: Soft Template Tuning for Few-Shot Adaptation
Paper and Code
Jul 18, 2022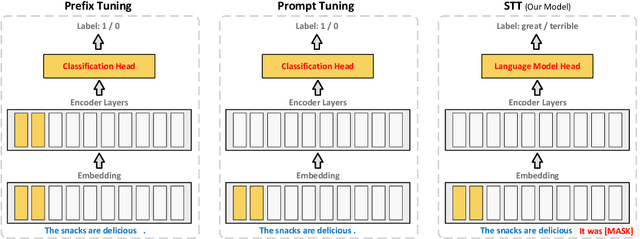
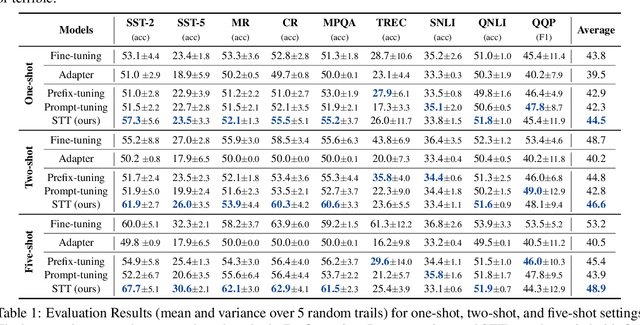
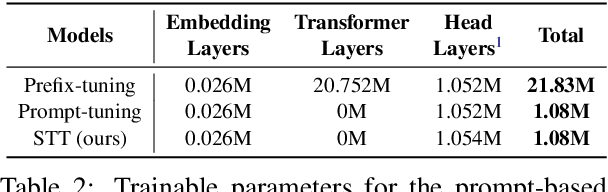
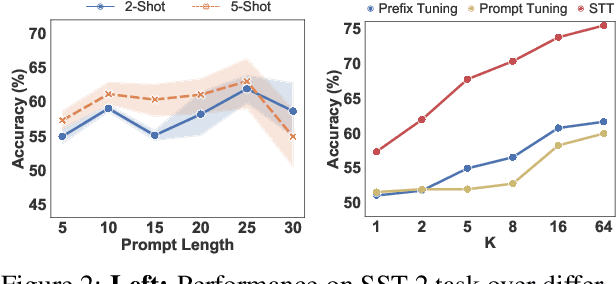
Prompt tuning has been an extremely effective tool to adapt a pre-trained model to downstream tasks. However, standard prompt-based methods mainly consider the case of sufficient data of downstream tasks. It is still unclear whether the advantage can be transferred to the few-shot regime, where only limited data are available for each downstream task. Although some works have demonstrated the potential of prompt-tuning under the few-shot setting, the main stream methods via searching discrete prompts or tuning soft prompts with limited data are still very challenging. Through extensive empirical studies, we find that there is still a gap between prompt tuning and fully fine-tuning for few-shot learning. To bridge the gap, we propose a new prompt-tuning framework, called Soft Template Tuning (STT). STT combines manual and auto prompts, and treats downstream classification tasks as a masked language modeling task. Comprehensive evaluation on different settings suggests STT can close the gap between fine-tuning and prompt-based methods without introducing additional parameters. Significantly, it can even outperform the time- and resource-consuming fine-tuning method on sentiment classification tasks.