 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Ensembles: an Approach to Reduce the Memory Footprint of Ensemble Methods
Paper and Code


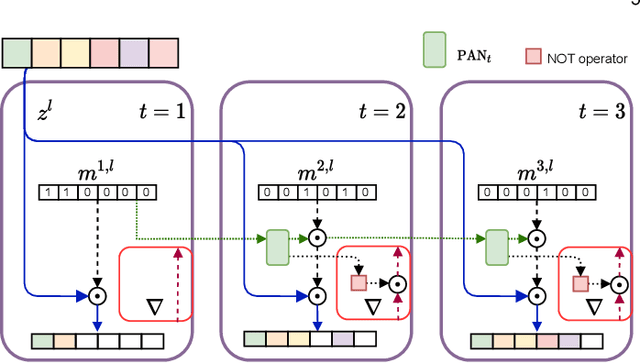

In this paper, we propose a novel ensembling technique for deep neural networks, which is able to drastically reduce the required memory compared to alternative approaches. In particular, we propose to extract multiple sub-networks from a single, untrained neural network by solving an end-to-end optimization task combining differentiable scaling over the original architecture, with multiple regularization terms favouring the diversity of the ensemble. Since our proposal aims to detect and extract sub-structures, we call it Structured Ensemble. On a large experimental evaluation, we show that our method can achieve higher or comparable accuracy to competing methods while requiring significantly less storage. In addition, we evaluate our ensembles in terms of predictive calibration and uncertainty, showing they compare favourably with the state-of-the-art. Finally, we draw a link with the continual learning literature, and we propose a modification of our framework to handle continuous streams of tasks with a sub-linear memory cost. We compare with a number of alternative strategies to mitigate catastrophic forgetting, highlighting advantages in terms of average accuracy and memory.