 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured-based Curriculum Learning for End-to-end English-Japanese Speech Translation
Paper and Code
Feb 13, 2018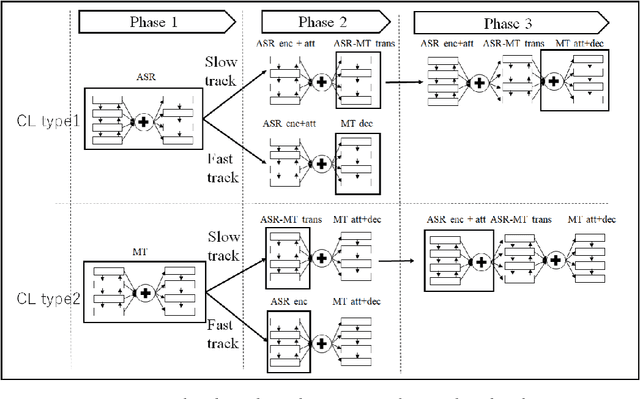
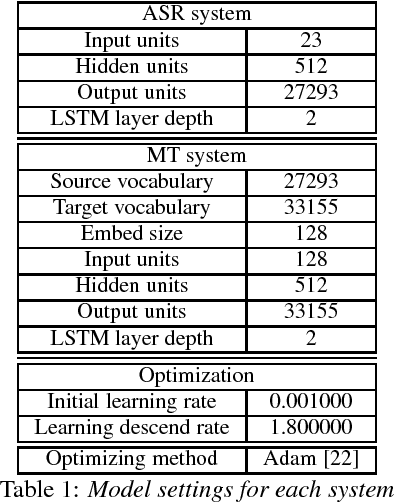

Sequence-to-sequence attentional-based neural network architectures have been shown to provide a powerful model for machine translation and speech recognition. Recently, several works have attempted to extend the models for end-to-end speech translation task. However, the usefulness of these models were only investigated on language pairs with similar syntax and word order (e.g., English-French or English-Spanish). In this work, we focus on end-to-end speech translation tasks on syntactically distant language pairs (e.g., English-Japanese) that require distant word reordering. To guide the encoder-decoder attentional model to learn this difficult problem, we propose a structured-based curriculum learning strategy. Unlike conventional curriculum learning that gradually emphasizes difficult data examples, we formalize learning strategies from easier network structures to more difficult network structures. Here, we start the training with end-to-end encoder-decoder for speech recognition or text-based machine translation task then gradually move to end-to-end speech translation task. The experiment results show that the proposed approach could provide significant improvements in comparison with the one without curriculum learning.