 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Adaptive Sequential Testing for Online False Discovery Rate Control
Paper and Code
Feb 28, 2020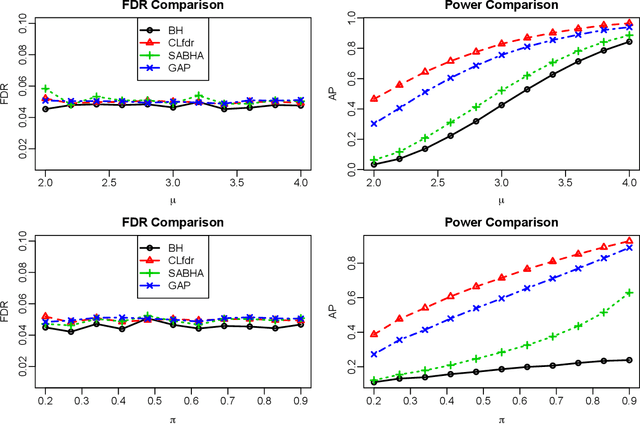
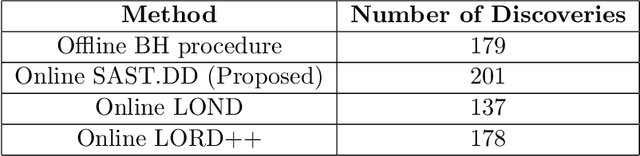
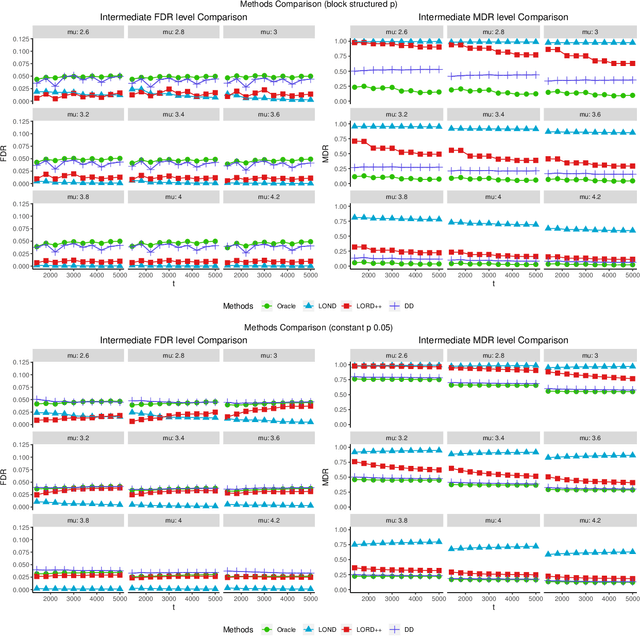
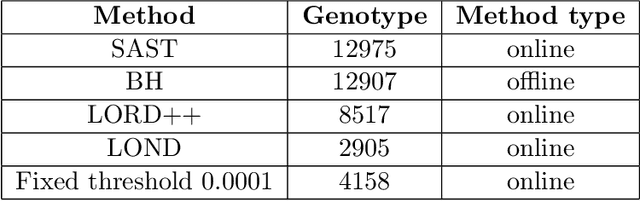
Consider the online testing of a stream of hypotheses where a real--time decision must be made before the next data point arrives. The error rate is required to be controlled at {all} decision points. Conventional \emph{simultaneous testing rules} are no longer applicable due to the more stringent error constraints and absence of future data. Moreover, the online decision--making process may come to a halt when the total error budget, or alpha--wealth, is exhausted. This work develops a new class of structure--adaptive sequential testing (SAST) rules for online false discover rate (FDR) control. A key element in our proposal is a new alpha--investment algorithm that precisely characterizes the gains and losses in sequential decision making. SAST captures time varying structures of the data stream, learns the optimal threshold adaptively in an ongoing manner and optimizes the alpha-wealth allocation across different time periods. We present theory and numerical results to show that the proposed method is valid for online FDR control and achieves substantial power gain over existing online testing rules.