 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Transfer Learning in NL-to-Bash Semantic Parsers
Paper and Code
Jul 31, 2023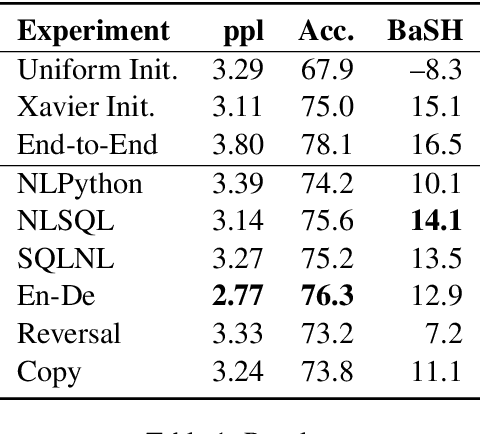
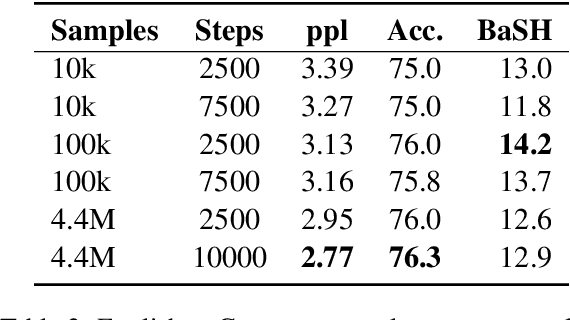
Large-scale pre-training has made progress in many fields of natural language processing, though little is understood about the design of pre-training datasets. We propose a methodology for obtaining a quantitative understanding of structural overlap between machine translation tasks. We apply our methodology to the natural language to Bash semantic parsing task (NLBash) and show that it is largely reducible to lexical alignment. We also find that there is strong structural overlap between NLBash and natural language to SQL. Additionally, we perform a study varying compute expended during pre-training on the English to German machine translation task and find that more compute expended during pre-training does not always correspond semantic representations with stronger transfer to NLBash.