 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Binary Sketching based on Subspace Tracking and Diagonal Uniformization
Paper and Code
Feb 08, 2018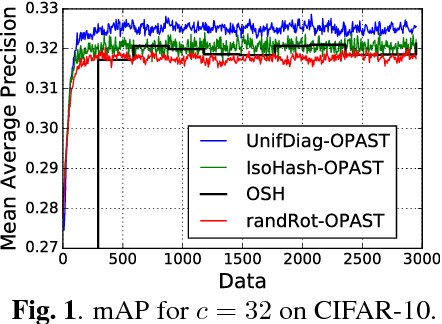
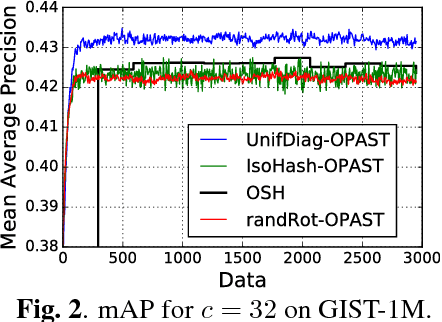
In this paper, we address the problem of learning compact similarity-preserving embeddings for massive high-dimensional streams of data in order to perform efficient similarity search. We present a new online method for computing binary compressed representations -sketches- of high-dimensional real feature vectors. Given an expected code length $c$ and high-dimensional input data points, our algorithm provides a $c$-bits binary code for preserving the distance between the points from the original high-dimensional space. Our algorithm does not require neither the storage of the whole dataset nor a chunk, thus it is fully adaptable to the streaming setting. It also provides low time complexity and convergence guarantees. We demonstrate the quality of our binary sketches through experiments on real data for the nearest neighbors search task in the online setting.