 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Algorithms for Diversity Maximization with Fairness Constraints
Paper and Code
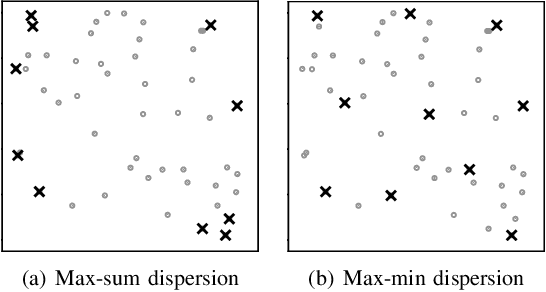

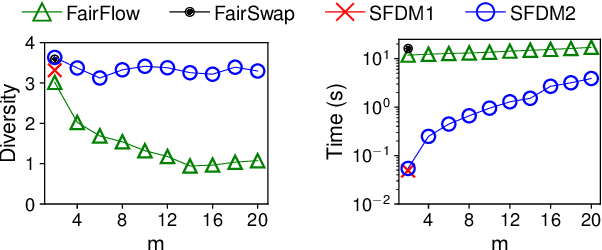

Diversity maximization is a fundamental problem with wide applications in data summarization, web search, and recommender systems. Given a set $X$ of $n$ elements, it asks to select a subset $S$ of $k \ll n$ elements with maximum \emph{diversity}, as quantified by the dissimilarities among the elements in $S$. In this paper, we focus on the diversity maximization problem with fairness constraints in the streaming setting. Specifically, we consider the max-min diversity objective, which selects a subset $S$ that maximizes the minimum distance (dissimilarity) between any pair of distinct elements within it. Assuming that the set $X$ is partitioned into $m$ disjoint groups by some sensitive attribute, e.g., sex or race, ensuring \emph{fairness} requires that the selected subset $S$ contains $k_i$ elements from each group $i \in [1,m]$. A streaming algorithm should process $X$ sequentially in one pass and return a subset with maximum \emph{diversity} while guaranteeing the fairness constraint. Although diversity maximization has been extensively studied, the only known algorithms that can work with the max-min diversity objective and fairness constraints are very inefficient for data streams. Since diversity maximization is NP-hard in general, we propose two approximation algorithms for fair diversity maximization in data streams, the first of which is $\frac{1-\varepsilon}{4}$-approximate and specific for $m=2$, where $\varepsilon \in (0,1)$, and the second of which achieves a $\frac{1-\varepsilon}{3m+2}$-approximation for an arbitrary $m$. Experimental results on real-world and synthetic datasets show that both algorithms provide solutions of comparable quality to the state-of-the-art algorithms while running several orders of magnitude faster in the streaming setting.