 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Sparse Subspace Clustering
Paper and Code
May 04, 2020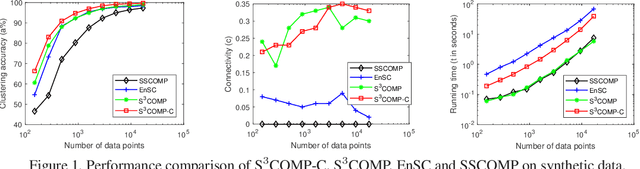



State-of-the-art subspace clustering methods are based on self-expressive model, which represents each data point as a linear combination of other data points. By enforcing such representation to be sparse, sparse subspace clustering is guaranteed to produce a subspace-preserving data affinity where two points are connected only if they are from the same subspace. On the other hand, however, data points from the same subspace may not be well-connected, leading to the issue of over-segmentation. We introduce dropout to address the issue of over-segmentation, which is based on randomly dropping out data points in self-expressive model. In particular, we show that dropout is equivalent to adding a squared $\ell_2$ norm regularization on the representation coefficients, therefore induces denser solutions. Then, we reformulate the optimization problem as a consensus problem over a set of small-scale subproblems. This leads to a scalable and flexible sparse subspace clustering approach, termed Stochastic Sparse Subspace Clustering, which can effectively handle large scale datasets. Extensive experiments on synthetic data and real world datasets validate the efficiency and effectiveness of our proposal.