Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Linear Contextual Bandits with Diverse Contexts
Paper and Code
Mar 05, 2020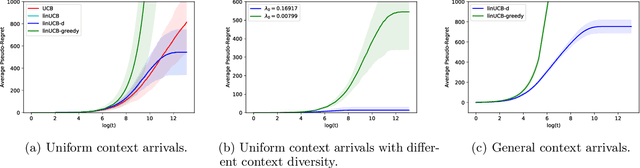
In this paper, we investigate the impact of context diversity on stochastic linear contextual bandits. As opposed to the previous view that contexts lead to more difficult bandit learning, we show that when the contexts are sufficiently diverse, the learner is able to utilize the information obtained during exploitation to shorten the exploration process, thus achieving reduced regret. We design the LinUCB-d algorithm, and propose a novel approach to analyze its regret performance. The main theoretical result is that under the diverse context assumption, the cumulative expected regret of LinUCB-d is bounded by a constant. As a by-product, our results improve the previous understanding of LinUCB and strengthen its performance guarantee.
* Accepted to AISTATS 2020
View paper on