 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Gradient Descent with Large Learning Rate
Paper and Code
Dec 17, 2020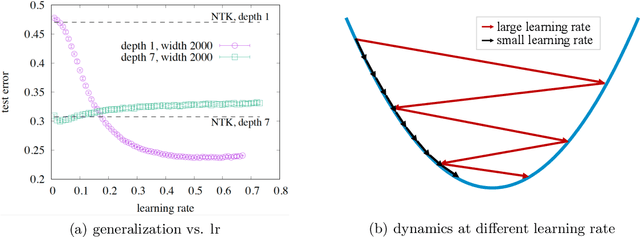
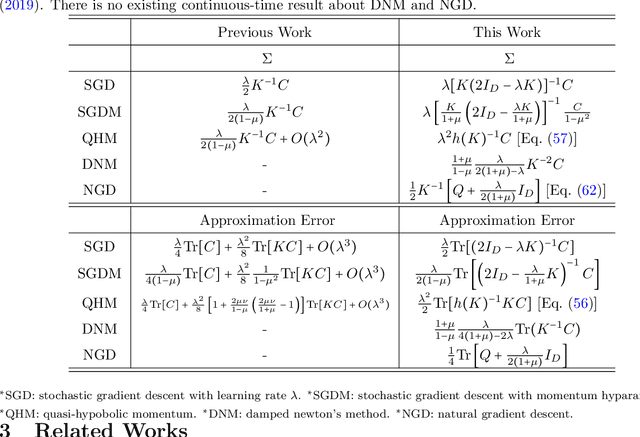
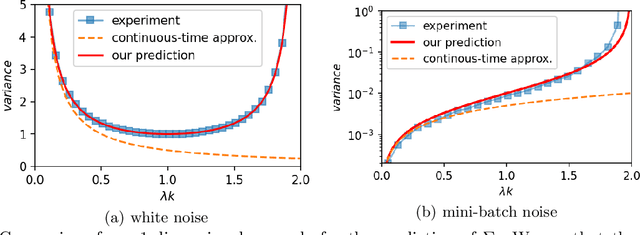
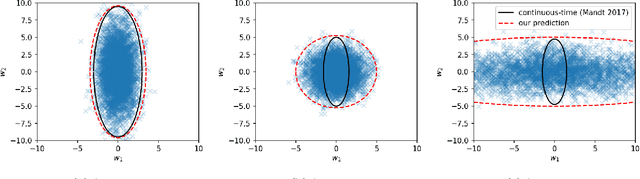
As a simple and efficient optimization method in deep learning, stochastic gradient descent (SGD) has attracted tremendous attention. In the vanishing learning rate regime, SGD is now relatively well understood, and the majority of theoretical approaches to SGD set their assumptions in the continuous-time limit. However, the continuous-time predictions are unlikely to reflect the experimental observations well because the practice often runs in the large learning rate regime, where the training is faster and the generalization of models are often better. In this paper, we propose to study the basic properties of SGD and its variants in the non-vanishing learning rate regime. The focus is on deriving exactly solvable results and relating them to experimental observations. The main contributions of this work are to derive the stable distribution for discrete-time SGD in a quadratic loss function with and without momentum. Examples of applications of the proposed theory considered in this work include the approximation error of variants of SGD, the effect of mini-batch noise, the escape rate from a sharp minimum, and and the stationary distribution of a few second order methods.