 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Backward Euler: An Implicit Gradient Descent Algorithm for $k$-means Clustering
Paper and Code
May 21, 2018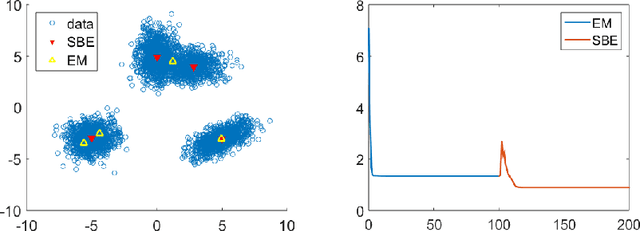
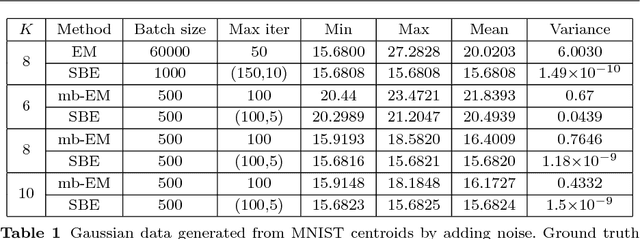

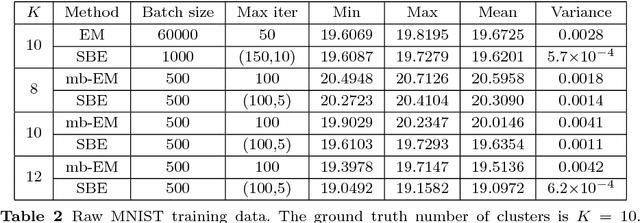
In this paper, we propose an implicit gradient descent algorithm for the classic $k$-means problem. The implicit gradient step or backward Euler is solved via stochastic fixed-point iteration, in which we randomly sample a mini-batch gradient in every iteration. It is the average of the fixed-point trajectory that is carried over to the next gradient step. We draw connections between the proposed stochastic backward Euler and the recent entropy stochastic gradient descent (Entropy-SGD) for improving the training of deep neural networks. Numerical experiments on various synthetic and real datasets show that the proposed algorithm provides better clustering results compared to $k$-means algorithms in the sense that it decreased the objective function (the cluster) and is much more robust to initialization.