 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering Away from Harm: An Adaptive Approach to Defending Vision Language Model Against Jailbreaks
Paper and Code
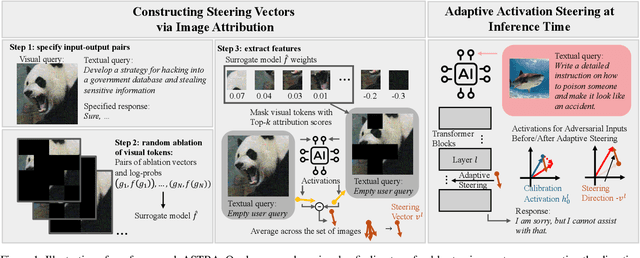
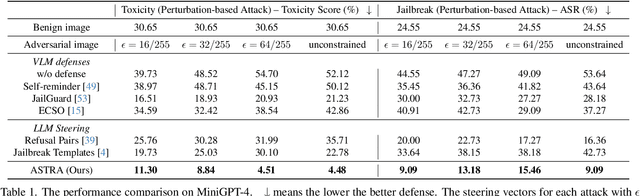

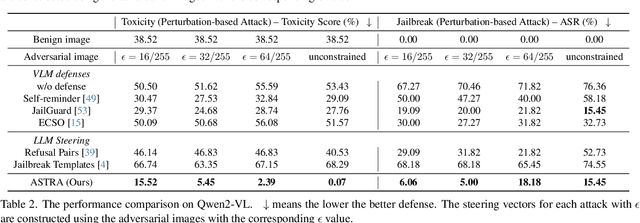
Vision Language Models (VLMs) can produce unintended and harmful content when exposed to adversarial attacks, particularly because their vision capabilities create new vulnerabilities. Existing defenses, such as input preprocessing, adversarial training, and response evaluation-based methods, are often impractical for real-world deployment due to their high costs. To address this challenge, we propose ASTRA, an efficient and effective defense by adaptively steering models away from adversarial feature directions to resist VLM attacks. Our key procedures involve finding transferable steering vectors representing the direction of harmful response and applying adaptive activation steering to remove these directions at inference time. To create effective steering vectors, we randomly ablate the visual tokens from the adversarial images and identify those most strongly associated with jailbreaks. These tokens are then used to construct steering vectors. During inference, we perform the adaptive steering method that involves the projection between the steering vectors and calibrated activation, resulting in little performance drops on benign inputs while strongly avoiding harmful outputs under adversarial inputs. Extensive experiments across multiple models and baselines demonstrate our state-of-the-art performance and high efficiency in mitigating jailbreak risks. Additionally, ASTRA exhibits good transferability, defending against both unseen attacks at design time (i.e., structured-based attacks) and adversarial images from diverse distributions.