 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStagewise Enlargement of Batch Size for SGD-based Learning
Paper and Code
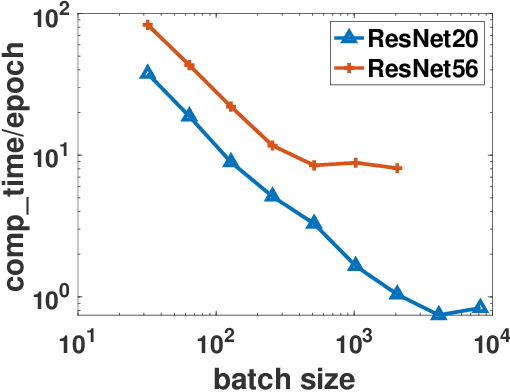
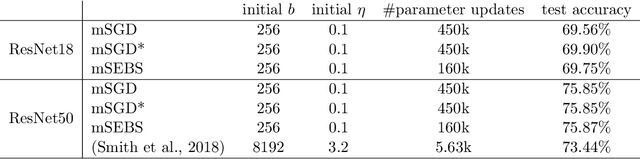
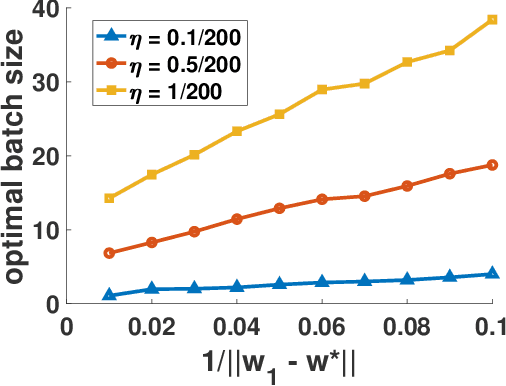
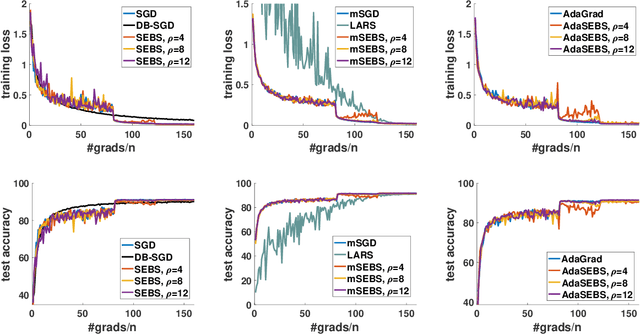
Existing research shows that the batch size can seriously affect the performance of stochastic gradient descent~(SGD) based learning, including training speed and generalization ability. A larger batch size typically results in less parameter updates. In distributed training, a larger batch size also results in less frequent communication. However, a larger batch size can make a generalization gap more easily. Hence, how to set a proper batch size for SGD has recently attracted much attention. Although some methods about setting batch size have been proposed, the batch size problem has still not been well solved. In this paper, we first provide theory to show that a proper batch size is related to the gap between initialization and optimum of the model parameter. Then based on this theory, we propose a novel method, called \underline{s}tagewise \underline{e}nlargement of \underline{b}atch \underline{s}ize~(\mbox{SEBS}), to set proper batch size for SGD. More specifically, \mbox{SEBS} adopts a multi-stage scheme, and enlarges the batch size geometrically by stage. We theoretically prove that, compared to classical stagewise SGD which decreases learning rate by stage, \mbox{SEBS} can reduce the number of parameter updates without increasing generalization error. SEBS is suitable for \mbox{SGD}, momentum \mbox{SGD} and AdaGrad. Empirical results on real data successfully verify the theories of \mbox{SEBS}. Furthermore, empirical results also show that SEBS can outperform other baselines.