 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStack-VS: Stacked Visual-Semantic Attention for Image Caption Generation
Paper and Code
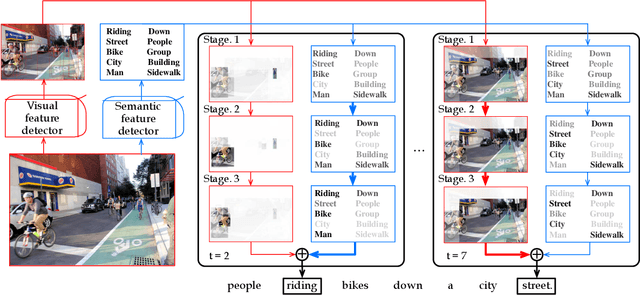
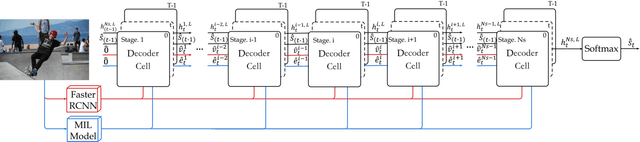
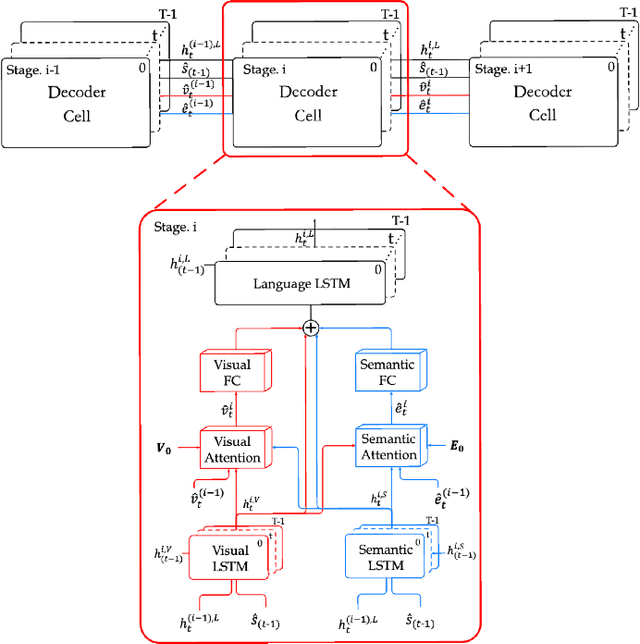
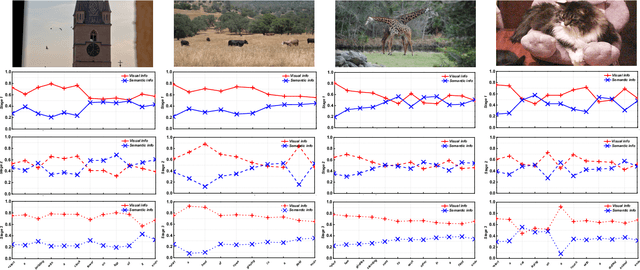
Recently, automatic image caption generation has been an important focus of the work on multimodal translation task. Existing approaches can be roughly categorized into two classes, i.e., top-down and bottom-up, the former transfers the image information (called as visual-level feature) directly into a caption, and the later uses the extracted words (called as semanticlevel attribute) to generate a description. However, previous methods either are typically based one-stage decoder or partially utilize part of visual-level or semantic-level information for image caption generation. In this paper, we address the problem and propose an innovative multi-stage architecture (called as Stack-VS) for rich fine-gained image caption generation, via combining bottom-up and top-down attention models to effectively handle both visual-level and semantic-level information of an input image. Specifically, we also propose a novel well-designed stack decoder model, which is constituted by a sequence of decoder cells, each of which contains two LSTM-layers work interactively to re-optimize attention weights on both visual-level feature vectors and semantic-level attribute embeddings for generating a fine-gained image caption. Extensive experiments on the popular benchmark dataset MSCOCO show the significant improvements on different evaluation metrics, i.e., the improvements on BLEU-4/CIDEr/SPICE scores are 0.372, 1.226 and 0.216, respectively, as compared to the state-of-the-arts.