 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Opponent Shaping in Differentiable Games
Paper and Code
Nov 20, 2018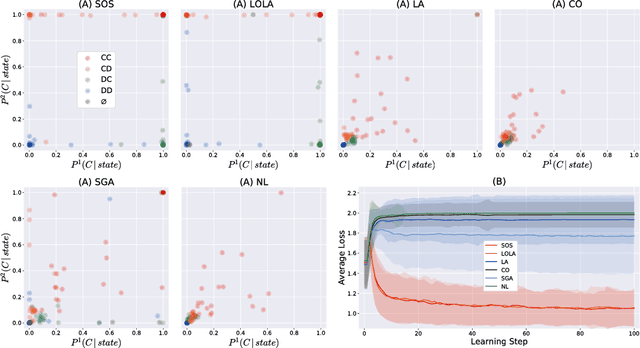
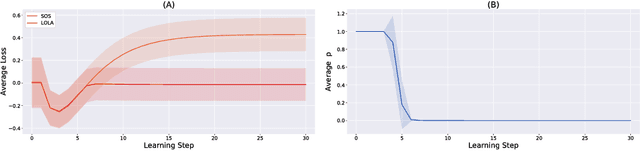
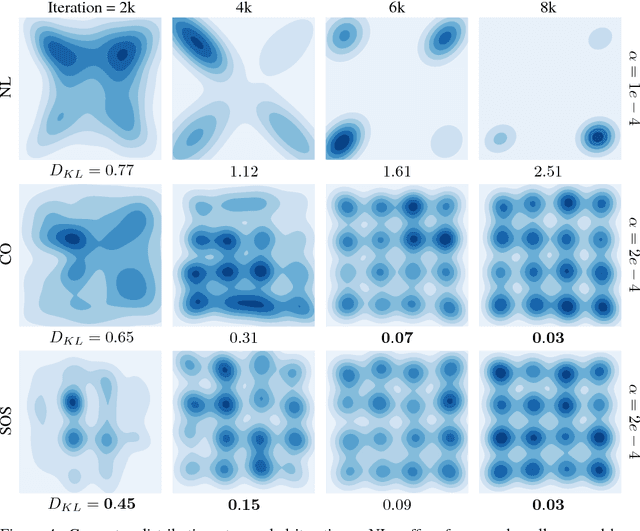

A growing number of learning methods are actually \emph{games} which optimise multiple, interdependent objectives in parallel -- from GANs and intrinsic curiosity to multi-agent RL. Opponent shaping is a powerful approach to improve learning dynamics in such games, accounting for the fact that the 'environment' includes agents adapting to one another's updates. Learning with Opponent-Learning Awareness (LOLA) is a recent algorithm which exploits this dynamic response and encourages cooperation in settings like the Iterated Prisoner's Dilemma. Although experimentally successful, we show that LOLA can exhibit 'arrogant' behaviour directly at odds with convergence. In fact, remarkably few algorithms have theoretical guarantees applying across all differentiable games. In this paper we present Stable Opponent Shaping (SOS), a new method that interpolates between LOLA and a stable variant named LookAhead. We prove that LookAhead locally converges and avoids strict saddles in \emph{all differentiable games}, the strongest results in the field so far. SOS inherits these desirable guarantees, while also shaping the learning of opponents and consistently either matching or outperforming LOLA experimentally.