 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStabilizing Q Learning Via Soft Mellowmax Operator
Paper and Code
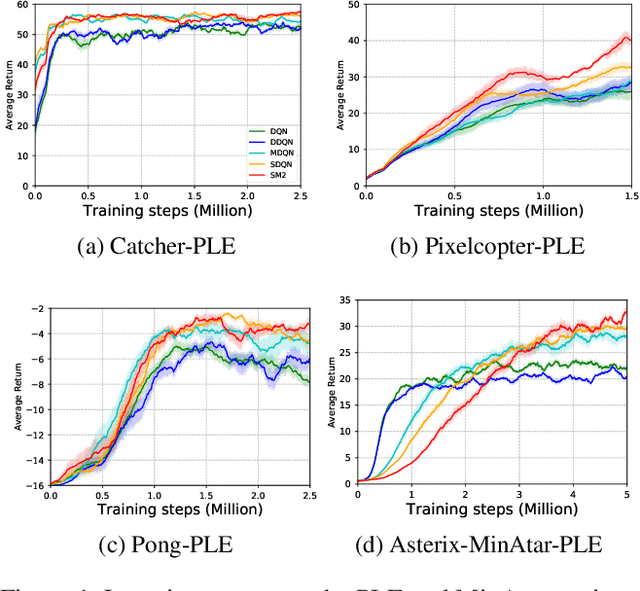

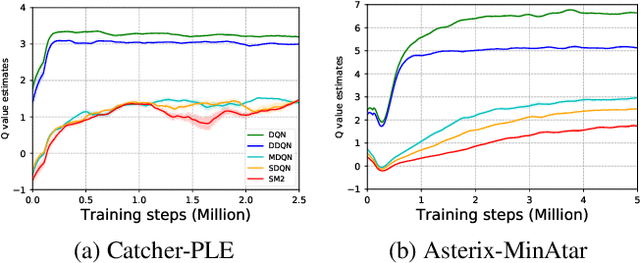

Learning complicated value functions in high dimensional state space by function approximation is a challenging task, partially due to that the max-operator used in temporal difference updates can theoretically cause instability for most linear or non-linear approximation schemes. Mellowmax is a recently proposed differentiable and non-expansion softmax operator that allows a convergent behavior in learning and planning. Unfortunately, the performance bound for the fixed point it converges to remains unclear, and in practice, its parameter is sensitive to various domains and has to be tuned case by case. Finally, the Mellowmax operator may suffer from oversmoothing as it ignores the probability being taken for each action when aggregating them. In this paper, we address all the above issues with an enhanced Mellowmax operator, named SM2 (Soft Mellowmax). Particularly, the proposed operator is reliable, easy to implement, and has provable performance guarantee, while preserving all the advantages of Mellowmax. Furthermore, we show that our SM2 operator can be applied to the challenging multi-agent reinforcement learning scenarios, leading to stable value function approximation and state of the art performance.