Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStability Guarantees for Continuous RL Control
Paper and Code
Sep 17, 2022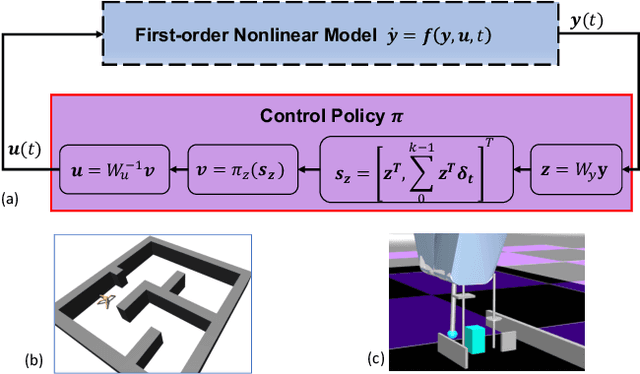
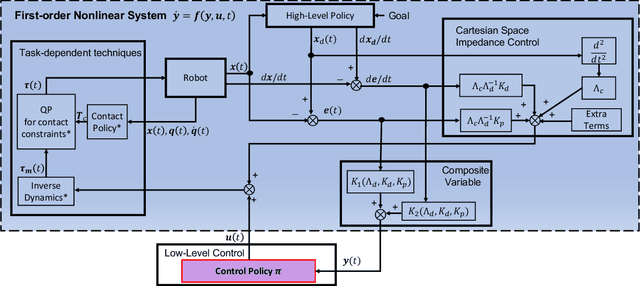
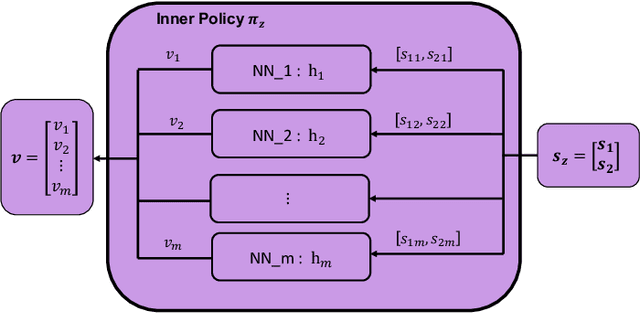
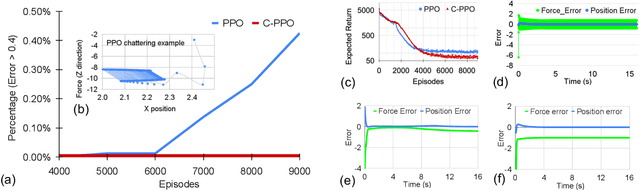
Lack of stability guarantees strongly limits the use of reinforcement learning (RL) in safety critical robotic applications. Here we propose a control system architecture for continuous RL control and derive corresponding stability theorems via contraction analysis, yielding constraints on the network weights to ensure stability. The control architecture can be implemented in general RL algorithms and improve their stability, robustness, and sample efficiency. We demonstrate the importance and benefits of such guarantees for RL on two standard examples, PPO learning of a 2D problem and HIRO learning of maze tasks.
View paper on