 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeST-P3: End-to-end Vision-based Autonomous Driving via Spatial-Temporal Feature Learning
Paper and Code


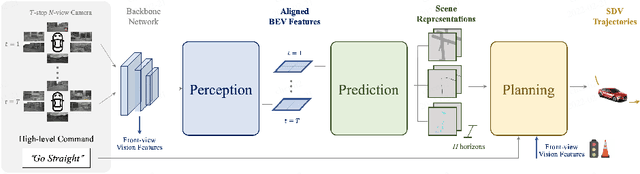
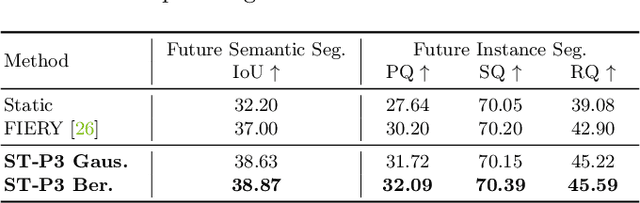
Many existing autonomous driving paradigms involve a multi-stage discrete pipeline of tasks. To better predict the control signals and enhance user safety, an end-to-end approach that benefits from joint spatial-temporal feature learning is desirable. While there are some pioneering works on LiDAR-based input or implicit design, in this paper we formulate the problem in an interpretable vision-based setting. In particular, we propose a spatial-temporal feature learning scheme towards a set of more representative features for perception, prediction and planning tasks simultaneously, which is called ST-P3. Specifically, an egocentric-aligned accumulation technique is proposed to preserve geometry information in 3D space before the bird's eye view transformation for perception; a dual pathway modeling is devised to take past motion variations into account for future prediction; a temporal-based refinement unit is introduced to compensate for recognizing vision-based elements for planning. To the best of our knowledge, we are the first to systematically investigate each part of an interpretable end-to-end vision-based autonomous driving system. We benchmark our approach against previous state-of-the-arts on both open-loop nuScenes dataset as well as closed-loop CARLA simulation. The results show the effectiveness of our method. Source code, model and protocol details are made publicly available at https://github.com/OpenPerceptionX/ST-P3.