 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSqueeze All: Novel Estimator and Self-Normalized Bound for Linear Contextual Bandits
Paper and Code
Jun 16, 2022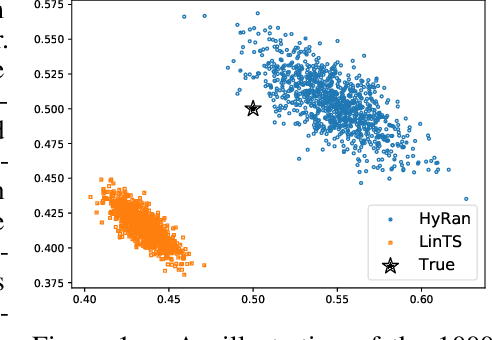
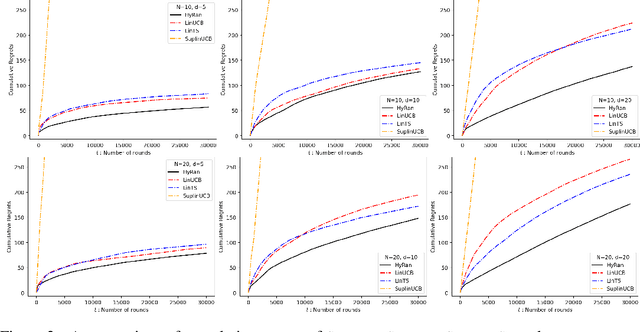
We propose a novel algorithm for linear contextual bandits with $O(\sqrt{dT \log T})$ regret bound, where $d$ is the dimension of contexts and $T$ is the time horizon. Our proposed algorithm is equipped with a novel estimator in which exploration is embedded through explicit randomization. Depending on the randomization, our proposed estimator takes contribution either from contexts of all arms or from selected contexts. We establish a self-normalized bound for our estimator, which allows a novel decomposition of the cumulative regret into additive dimension-dependent terms instead of multiplicative terms. We also prove a novel lower bound of $\Omega(\sqrt{dT})$ under our problem setting. Hence, the regret of our proposed algorithm matches the lower bound up to logarithmic factors. The numerical experiments support the theoretical guarantees and show that our proposed method outperforms the existing linear bandit algorithms.