 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplitting criteria for ordinal decision trees: an experimental study
Paper and Code
Dec 18, 2024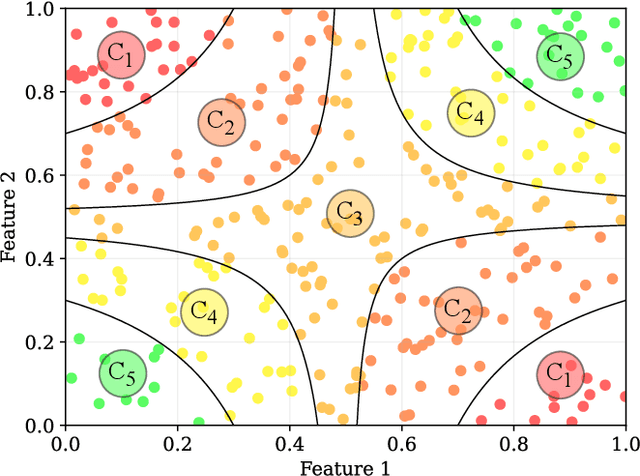
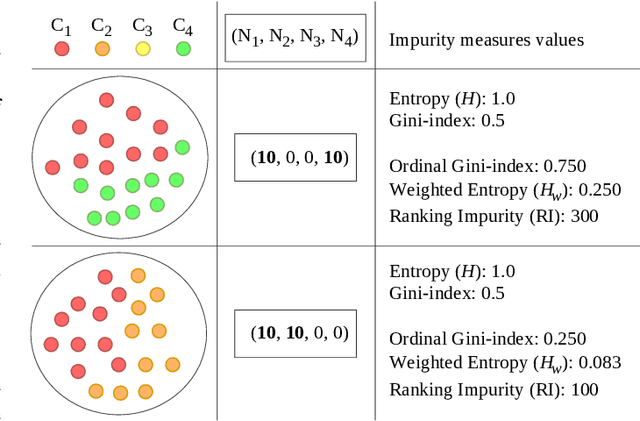
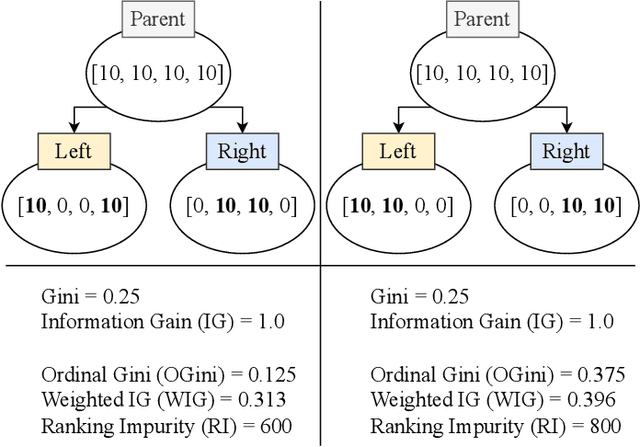
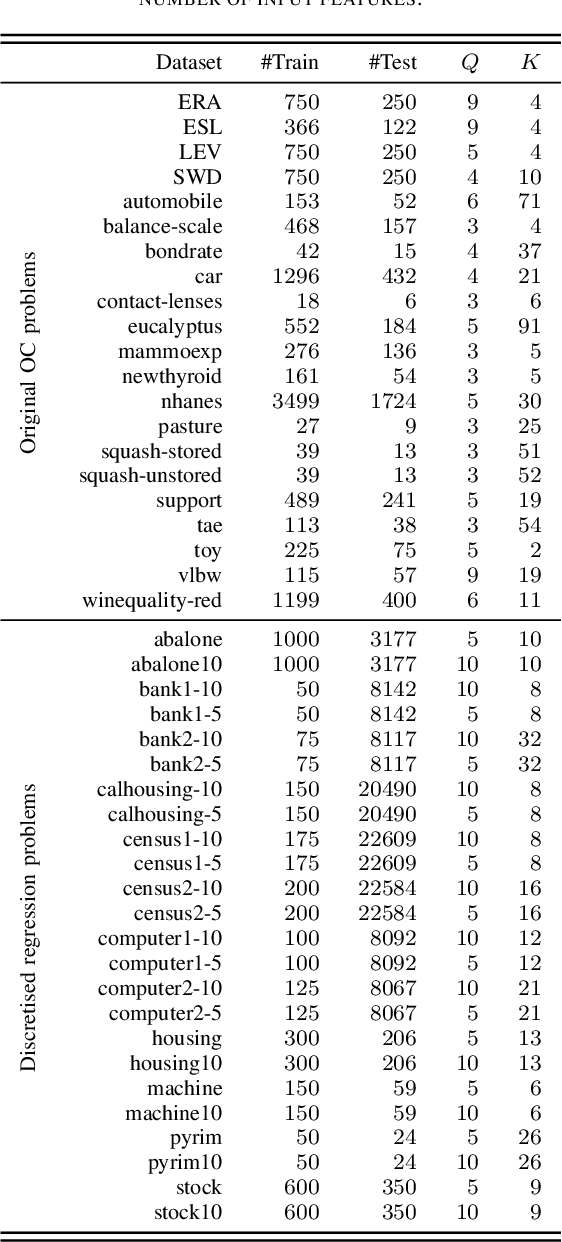
Ordinal Classification (OC) is a machine learning field that addresses classification tasks where the labels exhibit a natural order. Unlike nominal classification, which treats all classes as equally distinct, OC takes the ordinal relationship into account, producing more accurate and relevant results. This is particularly critical in applications where the magnitude of classification errors has implications. Despite this, OC problems are often tackled using nominal methods, leading to suboptimal solutions. Although decision trees are one of the most popular classification approaches, ordinal tree-based approaches have received less attention when compared to other classifiers. This work conducts an experimental study of tree-based methodologies specifically designed to capture ordinal relationships. A comprehensive survey of ordinal splitting criteria is provided, standardising the notations used in the literature for clarity. Three ordinal splitting criteria, Ordinal Gini (OGini), Weighted Information Gain (WIG), and Ranking Impurity (RI), are compared to the nominal counterparts of the first two (Gini and information gain), by incorporating them into a decision tree classifier. An extensive repository considering 45 publicly available OC datasets is presented, supporting the first experimental comparison of ordinal and nominal splitting criteria using well-known OC evaluation metrics. Statistical analysis of the results highlights OGini as the most effective ordinal splitting criterion to date. Source code, datasets, and results are made available to the research community.