 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpherical Frustum Sparse Convolution Network for LiDAR Point Cloud Semantic Segmentation
Paper and Code
Nov 29, 2023

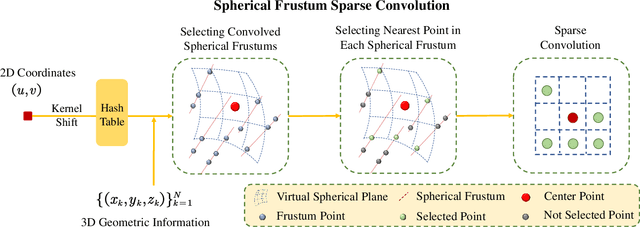

LiDAR point cloud semantic segmentation enables the robots to obtain fine-grained semantic information of the surrounding environment. Recently, many works project the point cloud onto the 2D image and adopt the 2D Convolutional Neural Networks (CNNs) or vision transformer for LiDAR point cloud semantic segmentation. However, since more than one point can be projected onto the same 2D position but only one point can be preserved, the previous 2D image-based segmentation methods suffer from inevitable quantized information loss. To avoid quantized information loss, in this paper, we propose a novel spherical frustum structure. The points projected onto the same 2D position are preserved in the spherical frustums. Moreover, we propose a memory-efficient hash-based representation of spherical frustums. Through the hash-based representation, we propose the Spherical Frustum sparse Convolution (SFC) and Frustum Fast Point Sampling (F2PS) to convolve and sample the points stored in spherical frustums respectively. Finally, we present the Spherical Frustum sparse Convolution Network (SFCNet) to adopt 2D CNNs for LiDAR point cloud semantic segmentation without quantized information loss. Extensive experiments on the SemanticKITTI and nuScenes datasets demonstrate that our SFCNet outperforms the 2D image-based semantic segmentation methods based on conventional spherical projection. The source code will be released later.