 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPECTRE: Defending Against Backdoor Attacks Using Robust Statistics
Paper and Code
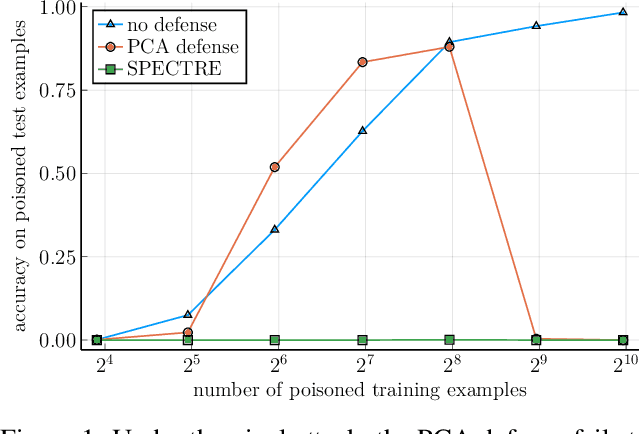

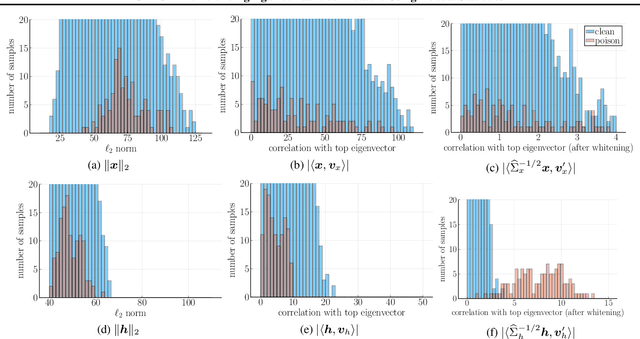
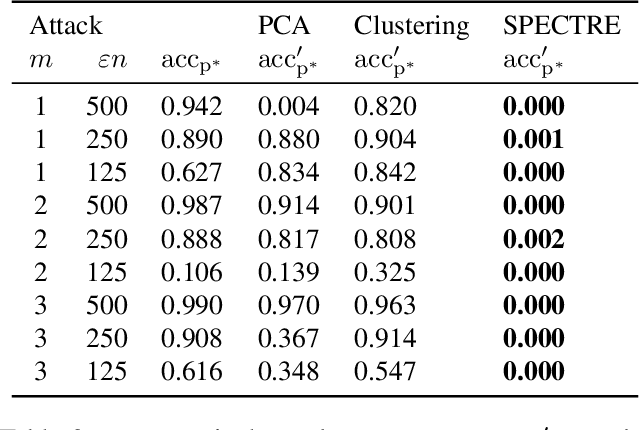
Modern machine learning increasingly requires training on a large collection of data from multiple sources, not all of which can be trusted. A particularly concerning scenario is when a small fraction of poisoned data changes the behavior of the trained model when triggered by an attacker-specified watermark. Such a compromised model will be deployed unnoticed as the model is accurate otherwise. There have been promising attempts to use the intermediate representations of such a model to separate corrupted examples from clean ones. However, these defenses work only when a certain spectral signature of the poisoned examples is large enough for detection. There is a wide range of attacks that cannot be protected against by the existing defenses. We propose a novel defense algorithm using robust covariance estimation to amplify the spectral signature of corrupted data. This defense provides a clean model, completely removing the backdoor, even in regimes where previous methods have no hope of detecting the poisoned examples. Code and pre-trained models are available at https://github.com/SewoongLab/spectre-defense .