 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral-Pruning: Compressing deep neural network via spectral analysis
Paper and Code
Aug 26, 2018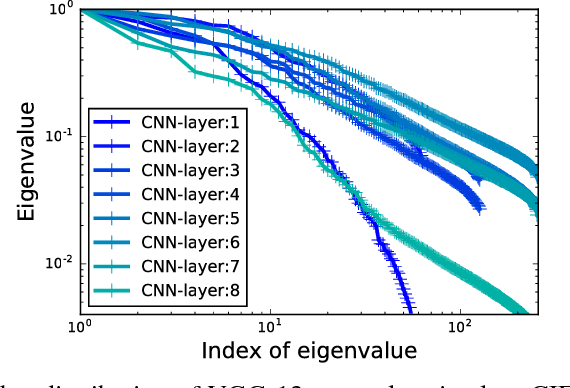

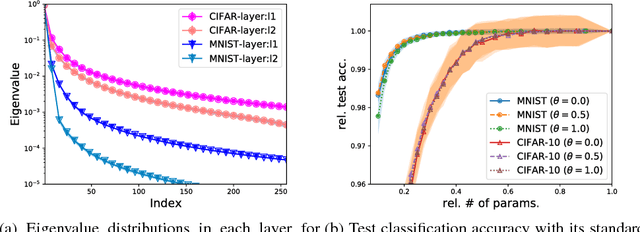
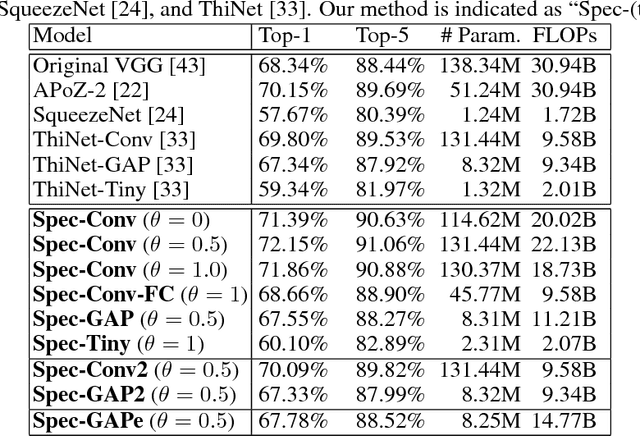
The model size of deep neural network is getting larger and larger to realize superior performance in complicated tasks. This makes it difficult to implement deep neural network in small edge-computing devices. To overcome this problem, model compression methods have been gathering much attention. However, there have been only few theoretical back-grounds that explain what kind of quantity determines the compression ability. To resolve this issue, we develop a new theoretical frame-work for model compression, and propose a new method called {\it Spectral-Pruning} based on the theory. Our theoretical analysis is based on the observation such that the eigenvalues of the covariance matrix of the output from nodes in the internal layers often shows rapid decay. We define "degree of freedom" to quantify an intrinsic dimensionality of the model by using the eigenvalue distribution and show that the compression ability is essentially controlled by this quantity. Along with this, we give a generalization error bound of the compressed model. Our proposed method is applicable to wide range of models, unlike the existing methods, e.g., ones possess complicated branches as implemented in SegNet and ResNet. Our method makes use of both "input" and "output" in each layer and is easy to implement. We apply our method to several datasets to justify our theoretical analyses and show that the proposed method achieves the state-of-the-art performance.