 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Modeling for Crowd Counting in Videos
Paper and Code
Jul 25, 2017

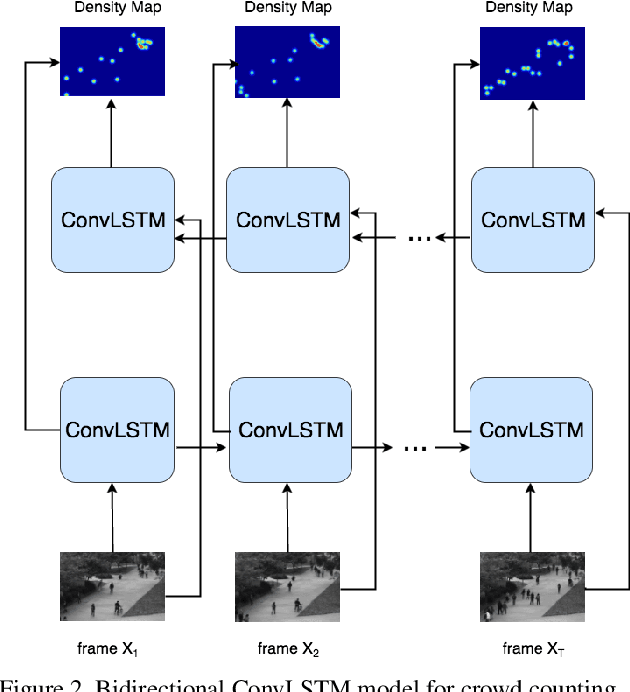

Region of Interest (ROI) crowd counting can be formulated as a regression problem of learning a mapping from an image or a video frame to a crowd density map. Recently, convolutional neural network (CNN) models have achieved promising results for crowd counting. However, even when dealing with video data, CNN-based methods still consider each video frame independently, ignoring the strong temporal correlation between neighboring frames. To exploit the otherwise very useful temporal information in video sequences, we propose a variant of a recent deep learning model called convolutional LSTM (ConvLSTM) for crowd counting. Unlike the previous CNN-based methods, our method fully captures both spatial and temporal dependencies. Furthermore, we extend the ConvLSTM model to a bidirectional ConvLSTM model which can access long-range information in both directions. Extensive experiments using four publicly available datasets demonstrate the reliability of our approach and the effectiveness of incorporating temporal information to boost the accuracy of crowd counting. In addition, we also conduct some transfer learning experiments to show that once our model is trained on one dataset, its learning experience can be transferred easily to a new dataset which consists of only very few video frames for model adaptation.