 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatially Invariant Unsupervised 3D Object Segmentation with Graph Neural Networks
Paper and Code
Jun 11, 2021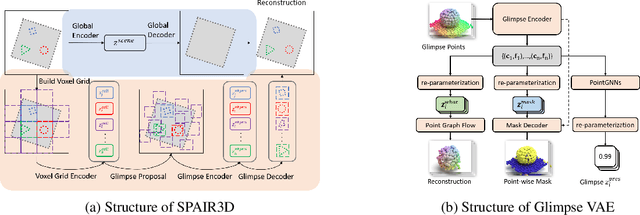
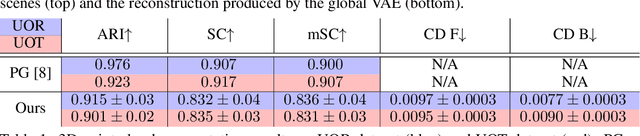
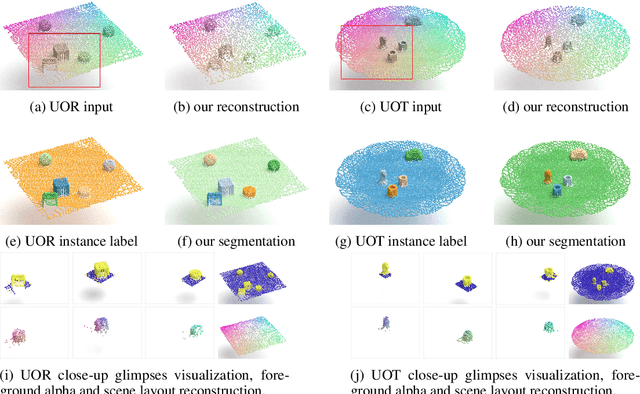

In this paper, we tackle the problem of unsupervised 3D object segmentation from a point cloud without RGB information. In particular, we propose a framework, SPAIR3D, to model a point cloud as a spatial mixture model and jointly learn the multiple-object representation and segmentation in 3D via Variational Autoencoders (VAE). Inspired by SPAIR, we adopt an object-specification scheme that describes each object's location relative to its local voxel grid cell rather than the point cloud as a whole. To model the spatial mixture model on point clouds, we derive the Chamfer Likelihood, which fits naturally into the variational training pipeline. We further design a new spatially invariant graph neural network to generate a varying number of 3D points as a decoder within our VAE. Experimental results demonstrate that SPAIR3D is capable of detecting and segmenting variable number of objects without appearance information across diverse scenes.