 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatially-Adaptive Feature Modulation for Efficient Image Super-Resolution
Paper and Code
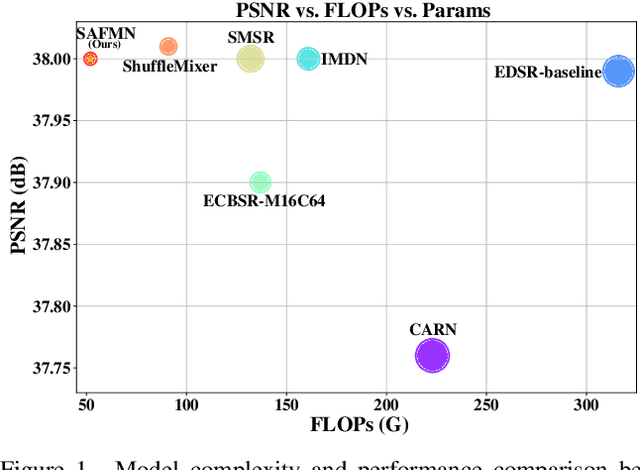



Although numerous solutions have been proposed for image super-resolution, they are usually incompatible with low-power devices with many computational and memory constraints. In this paper, we address this problem by proposing a simple yet effective deep network to solve image super-resolution efficiently. In detail, we develop a spatially-adaptive feature modulation (SAFM) mechanism upon a vision transformer (ViT)-like block. Within it, we first apply the SAFM block over input features to dynamically select representative feature representations. As the SAFM block processes the input features from a long-range perspective, we further introduce a convolutional channel mixer (CCM) to simultaneously extract local contextual information and perform channel mixing. Extensive experimental results show that the proposed method is $3\times$ smaller than state-of-the-art efficient SR methods, e.g., IMDN, in terms of the network parameters and requires less computational cost while achieving comparable performance. The code is available at https://github.com/sunny2109/SAFMN.