 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-Scale Aligned Network for Fine-Grained Recognition
Paper and Code
Jan 05, 2020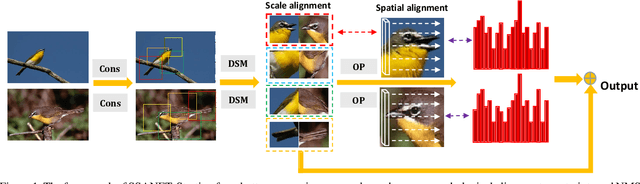



Existing approaches for fine-grained visual recognition focus on learning marginal region-based representations while neglecting the spatial and scale misalignments, leading to inferior performance. In this paper, we propose the spatial-scale aligned network (SSANET) and implicitly address misalignments during the recognition process. Especially, SSANET consists of 1) a self-supervised proposal mining formula with Morphological Alignment Constraints; 2) a discriminative scale mining (DSM) module, which exploits the feature pyramid via a circulant matrix, and provides the Fourier solver for fast scale alignments; 3) an oriented pooling (OP) module, that performs the pooling operation in several pre-defined orientations. Each orientation defines one kind of spatial alignment, and the network automatically determines which is the optimal alignments through learning. With the proposed two modules, our algorithm can automatically determine the accurate local proposal regions and generate more robust target representations being invariant to various appearance variances. Extensive experiments verify that SSANET is competent at learning better spatial-scale invariant target representations, yielding superior performance on the fine-grained recognition task on several benchmarks.