 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Knowledge Distillation to aid Visual Reasoning
Paper and Code
Dec 11, 2018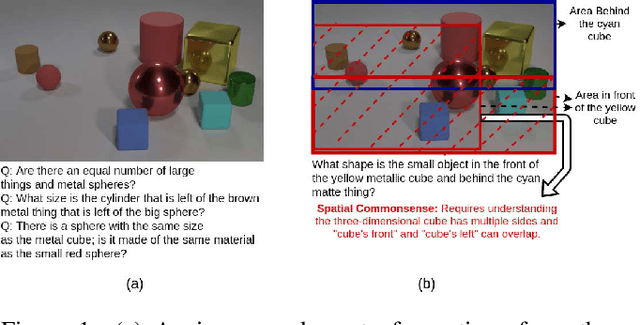

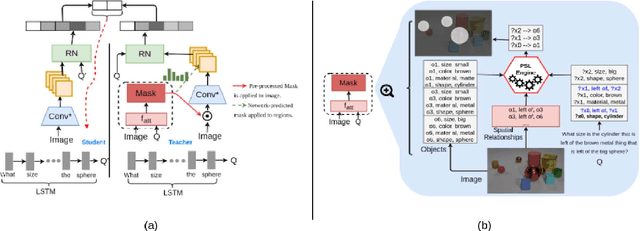
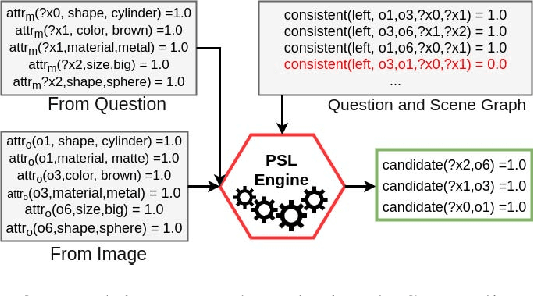
For tasks involving language and vision, the current state-of-the-art methods tend not to leverage any additional information that might be present to gather relevant (commonsense) knowledge. A representative task is Visual Question Answering where large diagnostic datasets have been proposed to test a system's capability of answering questions about images. The training data is often accompanied by annotations of individual object properties and spatial locations. In this work, we take a step towards integrating this additional privileged information in the form of spatial knowledge to aid in visual reasoning. We propose a framework that combines recent advances in knowledge distillation (teacher-student framework), relational reasoning and probabilistic logical languages to incorporate such knowledge in existing neural networks for the task of Visual Question Answering. Specifically, for a question posed against an image, we use a probabilistic logical language to encode the spatial knowledge and the spatial understanding about the question in the form of a mask that is directly provided to the teacher network. The student network learns from the ground-truth information as well as the teachers prediction via distillation. We also demonstrate the impact of predicting such a mask inside the teachers network using attention. Empirically, we show that both the methods improve the test accuracy over a state-of-the-art approach on a publicly available dataset.