 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Graph to Sequence Learning for Vision Conditioned Long Textual Sequence Generation
Paper and Code
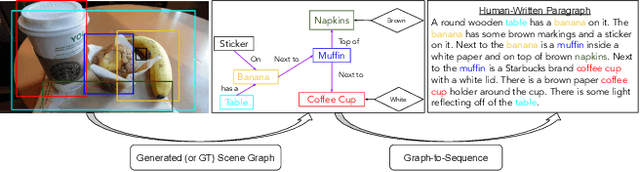
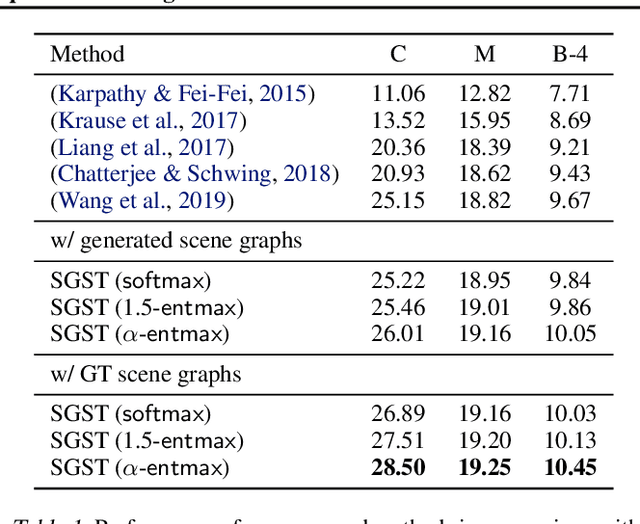
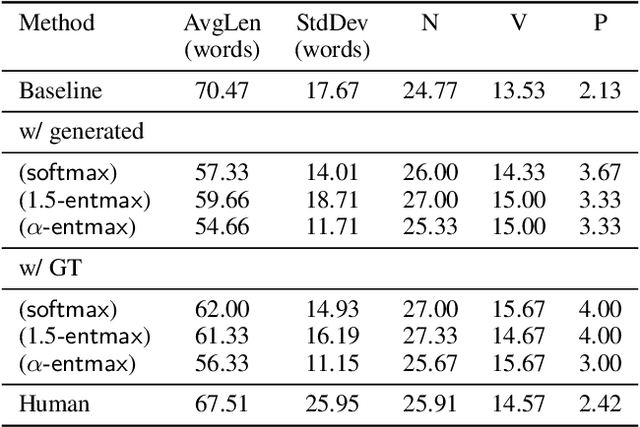
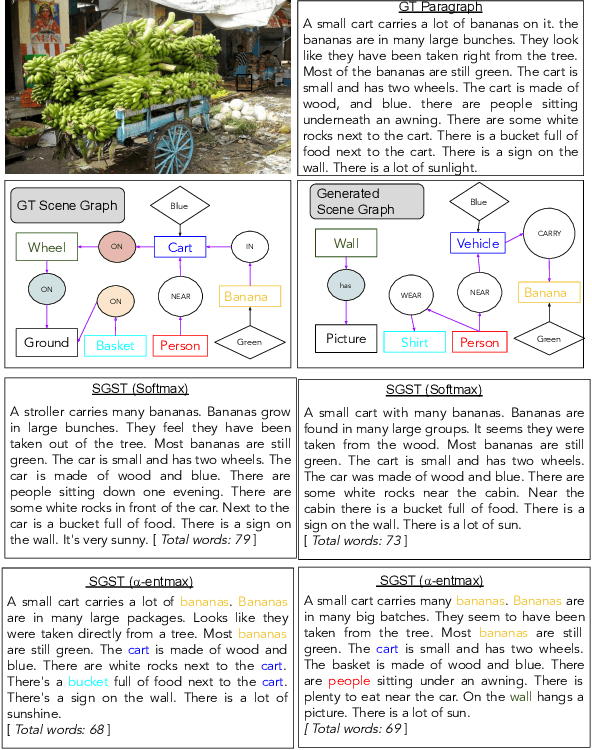
Generating longer textual sequences when conditioned on the visual information is an interesting problem to explore. The challenge here proliferate over the standard vision conditioned sentence-level generation (e.g., image or video captioning) as it requires to produce a brief and coherent story describing the visual content. In this paper, we mask this Vision-to-Sequence as Graph-to-Sequence learning problem and approach it with the Transformer architecture. To be specific, we introduce Sparse Graph-to-Sequence Transformer (SGST) for encoding the graph and decoding a sequence. The encoder aims to directly encode graph-level semantics, while the decoder is used to generate longer sequences. Experiments conducted with the benchmark image paragraph dataset show that our proposed achieve 13.3% improvement on the CIDEr evaluation measure when comparing to the previous state-of-the-art approach.