 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Black-box Video Attack with Reinforcement Learning
Paper and Code
Jan 11, 2020
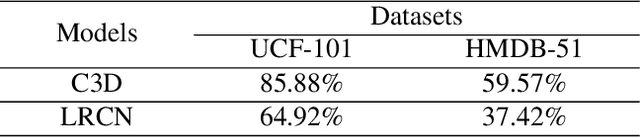


Adversarial attacks on video recognition models have been explored recently. However, most existing works treat each video frame equally and ignore their temporal interactions. To overcome this drawback, a few methods try to select some key frames, and then perform attacks based on them. Unfortunately, their selecting strategy is independent with the attacking step, therefore the resulting performance is limited. In this paper, we aim to attack video recognition task in the black-box setting. The difference is, we think the frame selection phase is closely relevant with the attacking phase. The reasonable key frames should be adjusted according to the feedback of attacking threat models. Based on this idea, we formulate the black-box video attacks into the Reinforcement Learning (RL) framework. Specifically, the environment in RL is set as the threat models, and the agent in RL plays the role of frame selecting and video attacking simultaneously. By continuously querying the threat models and receiving the feedback of predicted probabilities (reward), the agent adjusts its frame selection strategy and performs attacks (action). Step by step, the optimal key frames are selected and the smallest adversarial perturbations are achieved. We conduct a series of experiments with two mainstream video recognition models: C3D and LRCN on the public UCF-101 and HMDB-51 datasets. The results demonstrate that the proposed method can significantly reduce the perturbation of adversarial examples and attacking on the sparse video frames can have better attack effectiveness than attacking on each frame.