 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolution of Two-Player Zero-Sum Game by Successive Relaxation
Paper and Code
Jun 16, 2019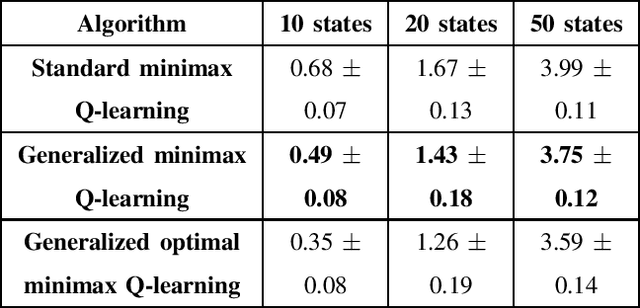
We consider the problem of two-player zero-sum game. In this setting, there are two agents working against each other. Both the agents observe the same state and the objective of the agents is to compute a strategy profile that maximizes their rewards. However, the reward of the second agent is negative of reward obtained by the first agent. Therefore, the objective of the second agent is to minimize the total reward obtained by the first agent. This problem is formulated as a min-max Markov game in the literature. The solution of this game, which is the max-min reward (of first player), starting from a given state is called the equilibrium value of the state. In this work, we compute the solution of the two-player zero-sum game utilizing the technique of successive relaxation. Successive relaxation has been successfully applied in the literature to compute a faster value iteration algorithm in the context of Markov Decision Processes. We extend the concept of successive relaxation to the two-player zero-sum games. We prove that, under a special structure, this technique computes the optimal solution faster than the techniques in the literature. We then derive a generalized minimax Q-learning algorithm that computes the optimal policy when the model information is not known. Finally, we prove the convergence of the proposed generalized minimax Q-learning algorithm.