 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Convex Quantization: Revisiting Vector Quantization with Convex Optimization
Paper and Code
Oct 04, 2023
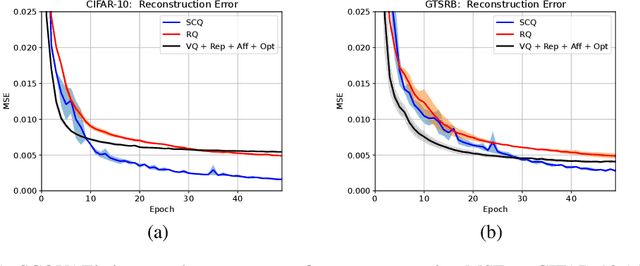

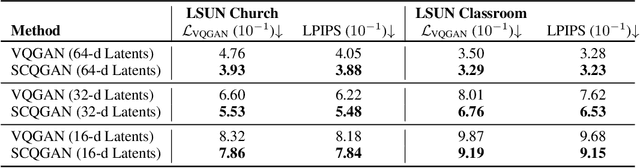
Vector Quantization (VQ) is a well-known technique in deep learning for extracting informative discrete latent representations. VQ-embedded models have shown impressive results in a range of applications including image and speech generation. VQ operates as a parametric K-means algorithm that quantizes inputs using a single codebook vector in the forward pass. While powerful, this technique faces practical challenges including codebook collapse, non-differentiability and lossy compression. To mitigate the aforementioned issues, we propose Soft Convex Quantization (SCQ) as a direct substitute for VQ. SCQ works like a differentiable convex optimization (DCO) layer: in the forward pass, we solve for the optimal convex combination of codebook vectors that quantize the inputs. In the backward pass, we leverage differentiability through the optimality conditions of the forward solution. We then introduce a scalable relaxation of the SCQ optimization and demonstrate its efficacy on the CIFAR-10, GTSRB and LSUN datasets. We train powerful SCQ autoencoder models that significantly outperform matched VQ-based architectures, observing an order of magnitude better image reconstruction and codebook usage with comparable quantization runtime.